
SQL-Cluster / Verfügbarkeitsgruppen
Einleitung
Für verschiedene Applikationen werden häufig SQL-Datenbanken für eine zentrale Ablage der Metainformationen benötigt. Damit diese Applikationen (welche häufig hochverfügbar aufgebaut werden) dann nicht ihren sog. “Single-Point-of-Failure” (= SPOF) bei der Datenbank haben, empfiehlt es sich, dass die Datenbanken dann eben auch hochverfügbar aufgebaut werden.
Das kann durch ein SQL-Cluster erreicht werden. Hier gibt es zwei Varianten:
- SQL-Failover-Cluster
- SQL-Verfügbarkeitsgruppen (engl. “AvailibilityGroups”, kurz “AGs”)
Während bei einem Failover-Cluster eine Seite komplett passiv und ungenutzt ist (ich gehe hier mal nur von einer SQL-Instanz aus), kann bei der zweiten Variante innerhalb von einer SQL-Instanz mehrere Verfügbarkeitsgruppen (bspw. getrennt für jede Applikation-Datenbank) angelegt werden – einzige Voraussetzung ist, dass der SQL-Server in der Enterprise- oder Developer-Edition betrieben wird. Bei einer Standard-Edition geht nur eine Verfügbarkeitsgruppe für eine Datenbank.
Zudem wird bei der ersten Variante ein geteiltes Storage benötigt, während bei der zweiten Variante jeder SQL-Serverdienst nur auf sein lokales Storage zugreift, dafür müssen beide Server in der Ordnerstruktur exakt gleich sein.
In diesem Artikel wird ein SQL-Cluster mit zwei Verfügbarkeitsgruppen eingerichtet:
- Verfügbarkeitsgruppe: Remote-Desktopservices Datenbank
- Verfügbarkeitsgruppe: Power BI Reportserver Datenbanken
Es wird die Developer-Edition verwendet, da es sich hierbei um eine DEMO-Umgebung handelt, ohne produktiven Workload.
Ablauf
- Bereitstellung der zwei VMs & Grundinstallation
- Installation & Konfiguration des Windows-Failovercluster
- Installation & Konfiguration der SQL-Server
- SQL Server Management Studio
- Anlegen einer Dummy-DB und erstellen der ersten Verfügbarkeitsgruppe
- Backup der Datenbank/en
- Downloads-Links für die benötigten Dinge
Los geht’s!
Bereitstellung der zwei VMs & Grundinstallation
Es werden folgende VMs verwendet: SQL01 & SQL02, beide in der DEMO-Domain als Memberserver. Die “Hardware” ist folgende:
- CPU: 4 Kerne
- RAM: 8GB
- HDD:
- 100GB Betriebssystem (NTFS)
- 20GB SQL-Server(NTFS)
- Netz: 1 virtuelle Netzwerkkarte
- IP SQL01: 192.168.11.51
- IP SQL02: 192.168.11.52
- Betriebssystem: Windows Server 2022 Standard
Installation & Konfiguration des Windows-Failovercluster
Hinweis:
Account for administering the cluster: When you first create a cluster or add servers to it, you must be logged on to the domain with an account that has administrator rights and permissions on all servers in that cluster. The account does not need to be a Domain Admins account, but can be a Domain Users account that is in the Administrators group on each clustered server. In addition, if the account is not a Domain Admins account, the account (or the group that the account is a member of) must be given the Create Computer Objects and Read All Properties permissions in the domain organizational unit (OU) that is will reside in.
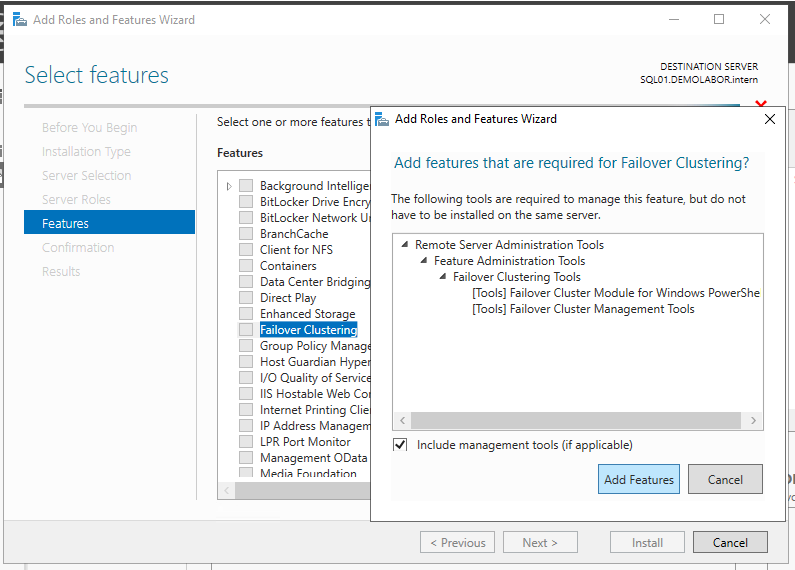
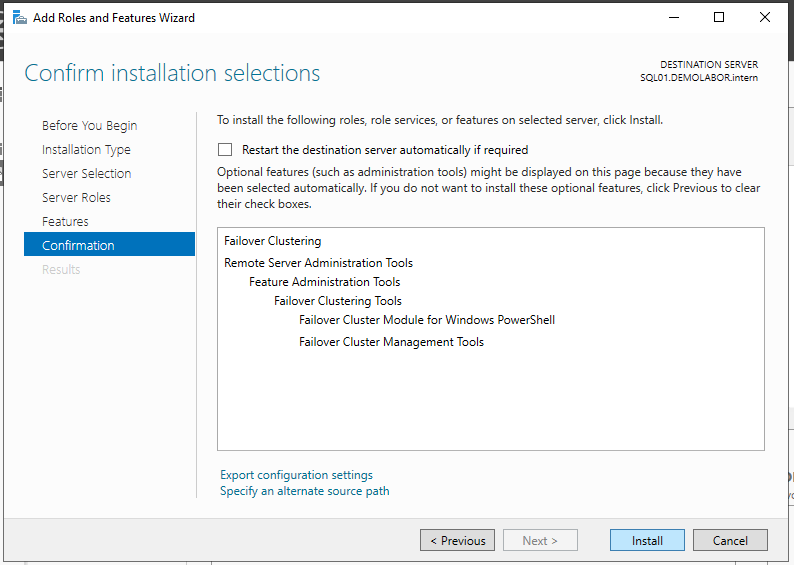
Zuerst muss das Feature “Failover Clustering” installiert werden, das wird, über den Server Manager gemacht. Die Abfrage, ob die Administrationstools mitinstalliert werden sollen, kann mit <Add Features> bestätigt werden.
Die Installation selbst läuft schnell durch und ist ohne Neustart fertig.
Jetzt kann der “Failover Cluster Manager” über den Server Manager im Menü “Tools” auf einem der beiden Server (ich nehme “SQL01”) gestartet werden.
Im “Failover Cluster Manager” nun einen Rechtsklick machen und im Kontextmenü auf “Create Cluster…” klicken (Alternativ auf der rechten Seitenleiste den selbigen Menüpunkt verwenden).
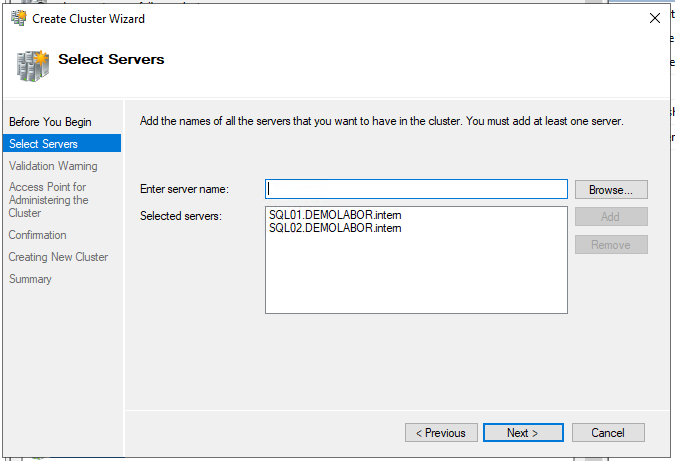
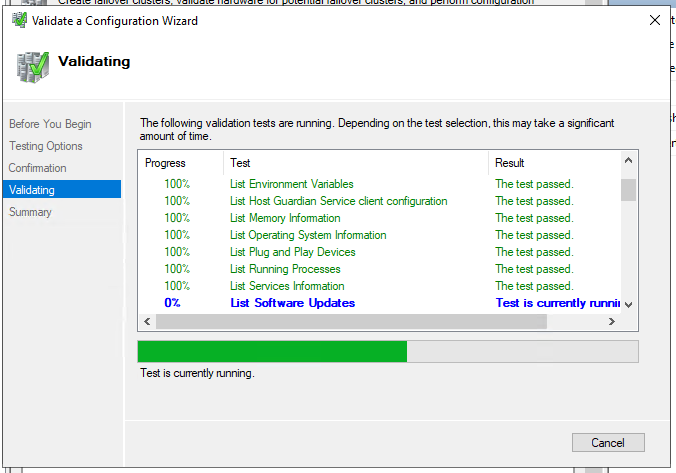
Mit Hilfe des Buttons <Browse> beide Server auswählen und hinzufügen; es wird ein kurzer Erreichbarkeits-Check durchgeführt und dann kann auf <Next> geklickt werden. Den anschließenden Test sollte man vor allem bei produktiven Umgebungen durchführen. Je nach System kann der Test durchaus 5-10 Minuten in Anspruch nehmen. Man sollte ihn sich kurz anschauen und prüfen, ob es gravierende Meldungen gibt. Wenn nicht (bzw. in Testumgebungen) kann man dann weitermachen.
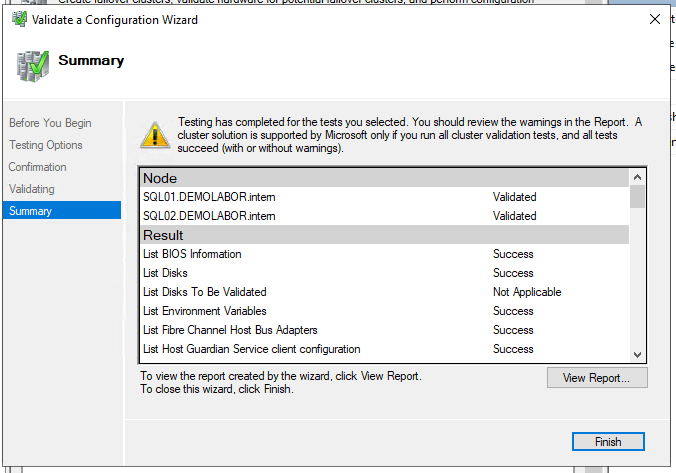
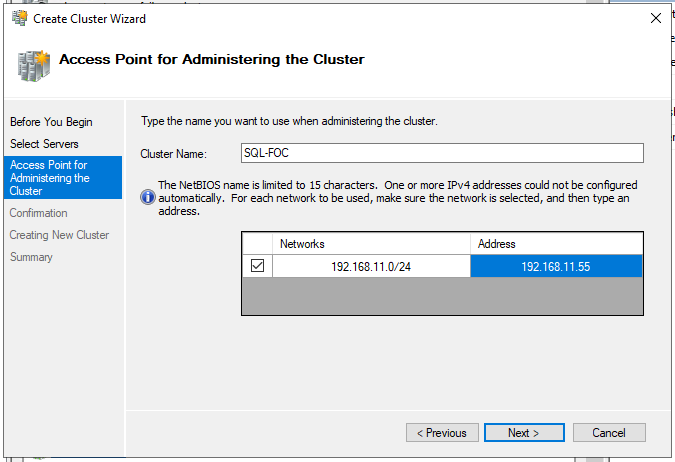
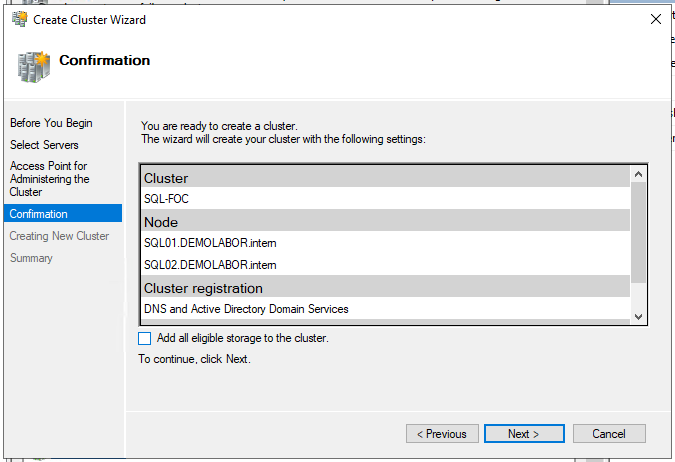
Jetzt wird der Clustername (max 15 Zeichen!) und die Cluster-IP vergeben. Im anschließenden Schritt “Confirmation” wird der Haken “Add all eligible storage to the cluster” entfernt, da an dieser Stelle kein Storage hinzugefügt werden soll; danach mit <Next> die Anlage des Clusters starten. Dieser Vorgang sollte nicht länger als 2-3 Minuten dauern und ohne Fehler abschließen. Mit Schließen des Einrichtungsassistenten ändert sich dann die Ansicht im “Failover Cluster Manager” und man sieht das Cluster mit allen Bestandteilen.



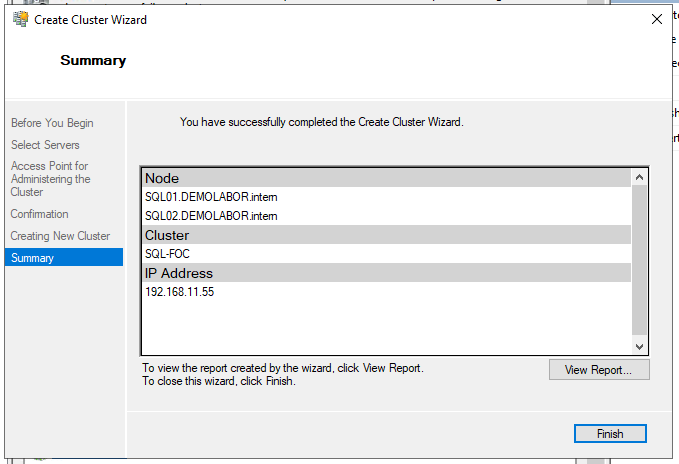

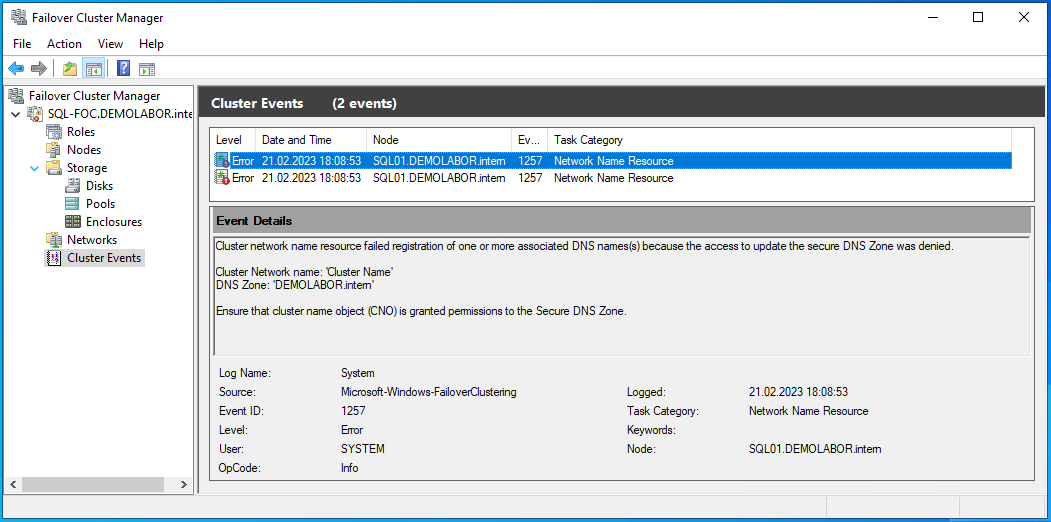
Unter Umständen zeigen die “Cluster Events” eine Fehlermeldung (Event ID 1257) an:
Cluster network name resource failed registration of one or more associated DNS names(s) because the access to update the secure DNS Zone was denied.
Cluster Network name: ‘Cluster Name’
DNS Zone: ‘DEMOLABOR.intern’Ensure that cluster name object (CNO) is granted permissions to the Secure DNS Zone.
Diese Meldung kann sich alle 15 Minuten wiederholen.
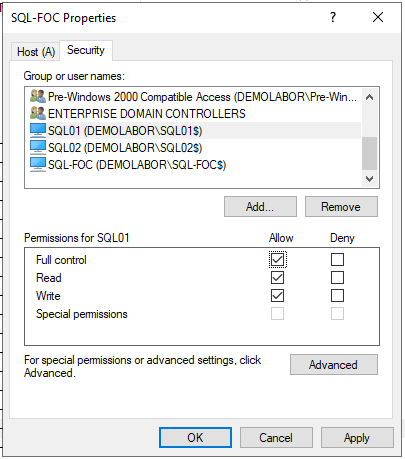
In diesem Fall auf dem DNS-Server beim A-Record “SQL-FOC” und beim PTR-Record “192.168.11.55” die Computerobjekte hinzufügen und mit “Full Control” berechtigen:
- SQL01
- SQL02
- SQL-FOC

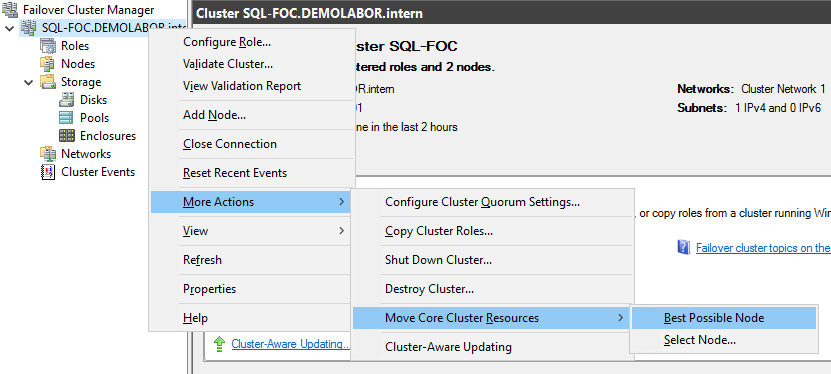
Zudem kann man das Cluster jetzt schon grundtesten, indem man einen Test-Schwenk ausführt. Hierzu einen Rechtsklick auf den Clusternamen “SQL-FOC.DEMOLABOR.intern” machen und im Kontextmenü “More Actions > Move Core Cluster Resources > Best Possible Node” auswählen. Im Hintergrund sieht man dann, wie die Kernkomponente des Clusters geschwenkt wird. Hierbei sollte dann ebenfalls keine neuen Einträge im “Cluster Events” auftauchen. Über den selben Menüpunkt kann man dann wieder auf “SQL01” zurückschwenken. Dieser Schwenk ist unabhängig der Rollen, die im Cluster noch hinzugefügt werden.

Optimaler Weise richtet man noch eine sog. “Witness” ein, das ist gerade bei einem 2-Knoten-Cluster wichtig, denn wenn ein Server heruntergefahren wird (oder ausfällt), dann sind 50% des Clusters weg und das Cluster fährt sich als Ganzes herunter. Durch den “Witness” gibt es quasi einen dritten “Knoten” im Verbund und falls ein Knoten nicht erreichbar ist, sind dann der verbleibende Knoten, plus der “Witness” in Summe noch “2 von 3” (also 66,6%) des Clusters und das Cluster im Ganzen bleibt bestehen.
Bedeutet aber auch: Sofern man die Möglichkeiten hat, sollte man mindestens ein 3 Knoten-Cluster bauen, um den Ausfall eines Knotens völlig problemlos abzufangen.
Installation & Konfiguration der SQL-Server
Jetzt geht es an die Installation der beiden SQL-Server.
Wichtig: Die Installation muss auf beiden Servern identisch sein!
Als kleine Vorbereitung werden vorher noch zwei Separate Service-Accounts für die SQL-Dienste angelegt:
- SA-SQLENGINE
- SA-SQLAGENT
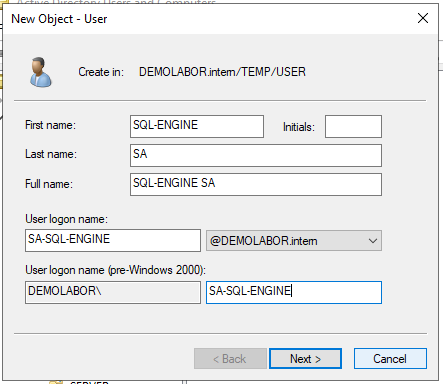



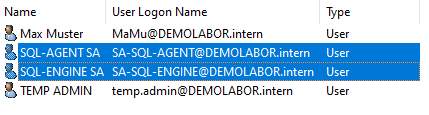
Damit es nicht zu komplex wird, sind diese beiden Accounts als klassische Accounts vom Typ “User” angelegt. Natürlich ist es im Rahmen der Sicherheit besser, wenn diese Accounts direkt als sog. “Group managed Service Accounts” (= kurz “gMSA”) angelegt werden würden.
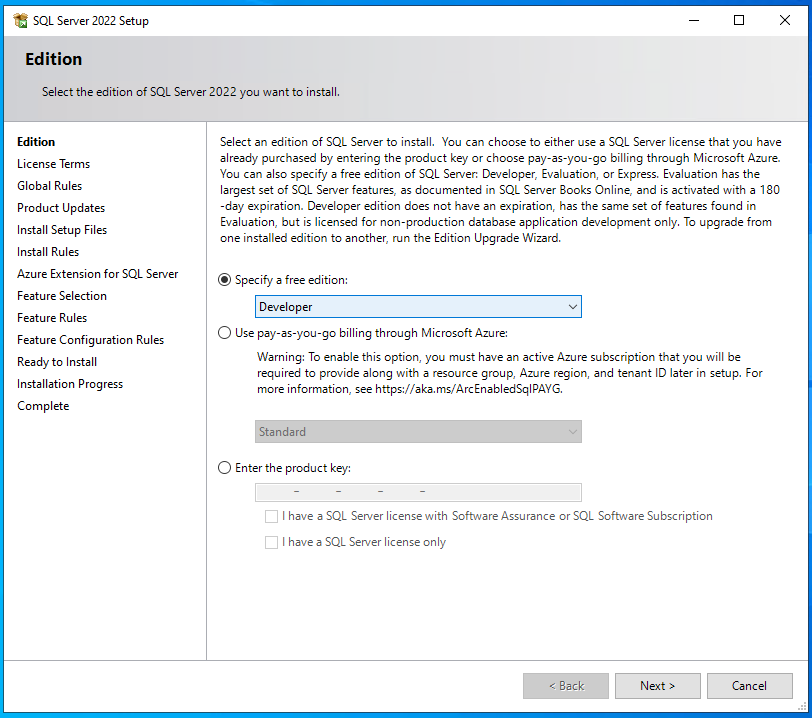
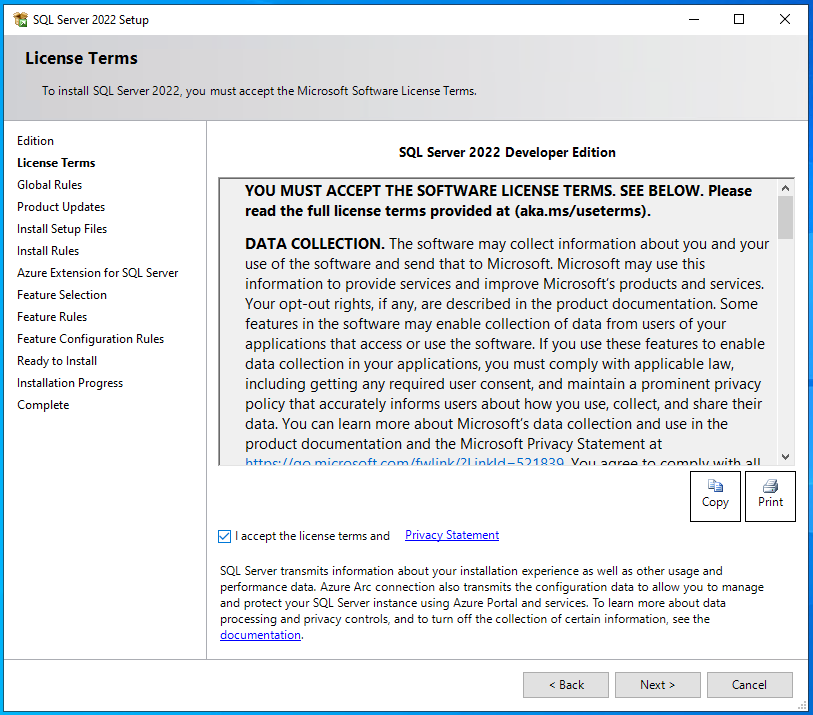
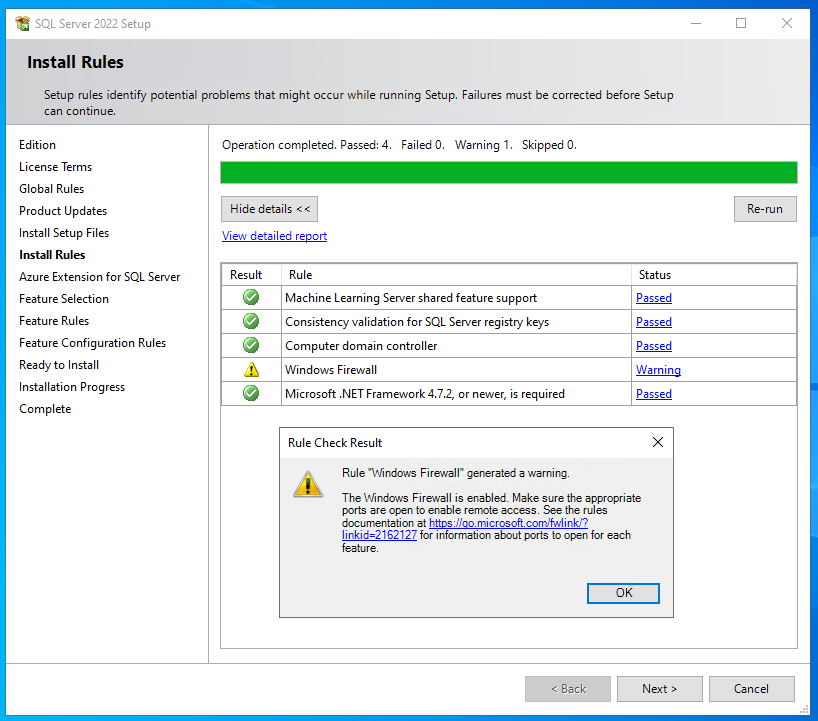
Für die Installation lege ich zuerst virtuell das ISO-Image (Download siehe Kapitel 5) ein und starte dann auf den VMs im Windows-Explorer auf dem DVD-Laufwerk die Datei “setup.exe” als Administrator. Es erscheint nach einer Weile das “SQL Server Installation Center”. Hier auf der linken Seite zu “Installation” wechseln und dann auf der rechten Seite den Punkt “New SQL Server standalone installation or add features to an existing installation” anklicken. Damit startet dann ein neues Fenster, welches das “SQL Server 2022 Setup” ist. Hier gibt es einen kleinen Unterschied zu früheren Versionen, denn zwischen “Specify a free edition” und “Enter the product key” ist nun noch ein “Use pay-as-you-go billing through Microsoft Azure” hinzugekommen. Für die Demo-Umgebung (und jede beliebige Testumgebung, ohne produktive Workloads) wird oben bei “Specify a free edition” der Menüpunkt “Developer” ausgewählt und auf <Next> geklickt. Direkt danach wird der Lizenzvertrag akzeptiert und erneut auf <Next> geklickt. Es folgen einige automatische Überprüfungen und das Ergebnis sollte sein, dass alle Haken auf grün sind, lediglich der Punkt “Windows Firewall” kann eine Warnung anzeigen, was aber nicht tragisch ist, denn man wird nur darauf hingewiesen, dass bei aktiver Windows Firewall noch Portfreigaben notwendig sein können; jetzt einfach wieder auf <Next> klicken.
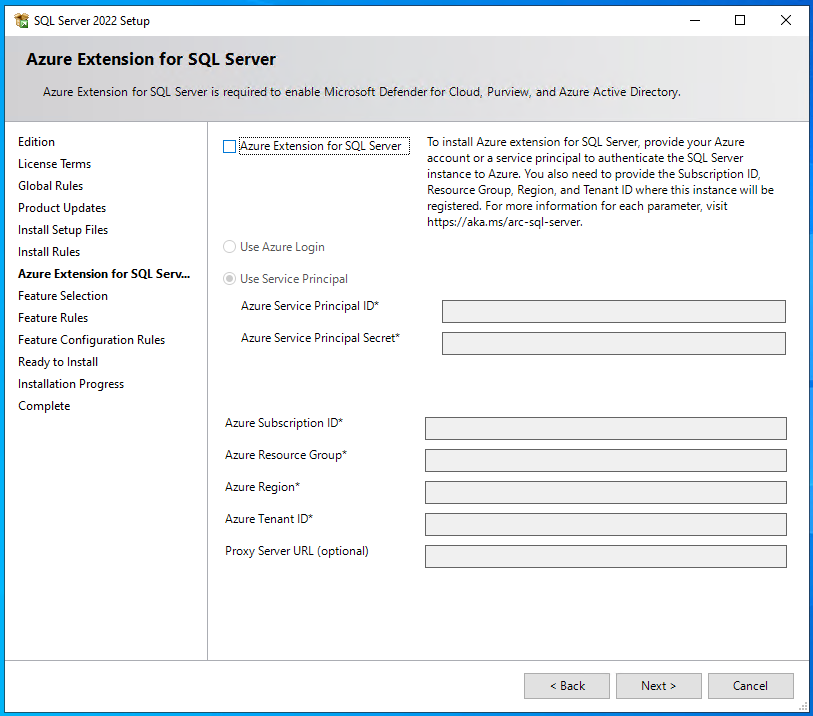
Der nächste Schritt ist ebenfalls neu; hier gibt es die Möglichkeit deine Azure Erweiterung für SQL-Server zu installieren, dazu einfach entweder mithilfe “Use Service Principal” oder “Use Azure Login” zum Tenant verbinden. Ich lasse diesen Schritt aus und nehme den Haken bei “Azure Extension for SQL Server” raus.
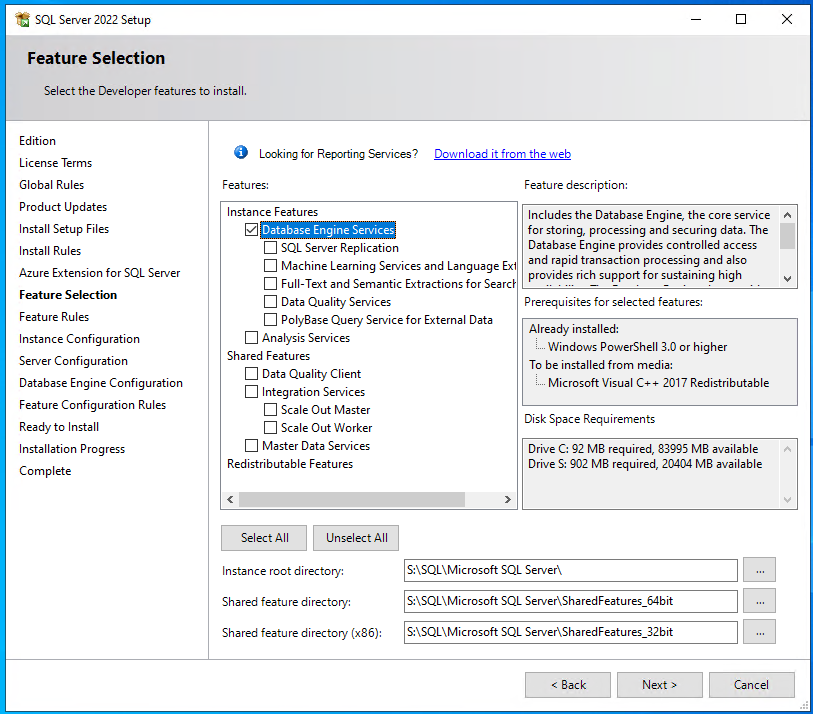
Jetzt folgt die Auswahl der zu installierenden Features und (ganz wichtig) auch den Pfad, wo das ganze hin installiert werden soll. Ich stelle folgendes ein:
- Features:
- Database Engine Services
- Pfade:
- Instance root directory: S:\SQL\Microsoft SQL Server\
- Shared feature directory: S:\SQL\Microsoft SQL Server\SharedFeatures_64bit
- Shared feature directory (x86): S:\SQL\Microsoft SQL Server\SharedFeatures_32bit
Anschließend mit dem Button <Next> zum nächsten Schritt gehen.
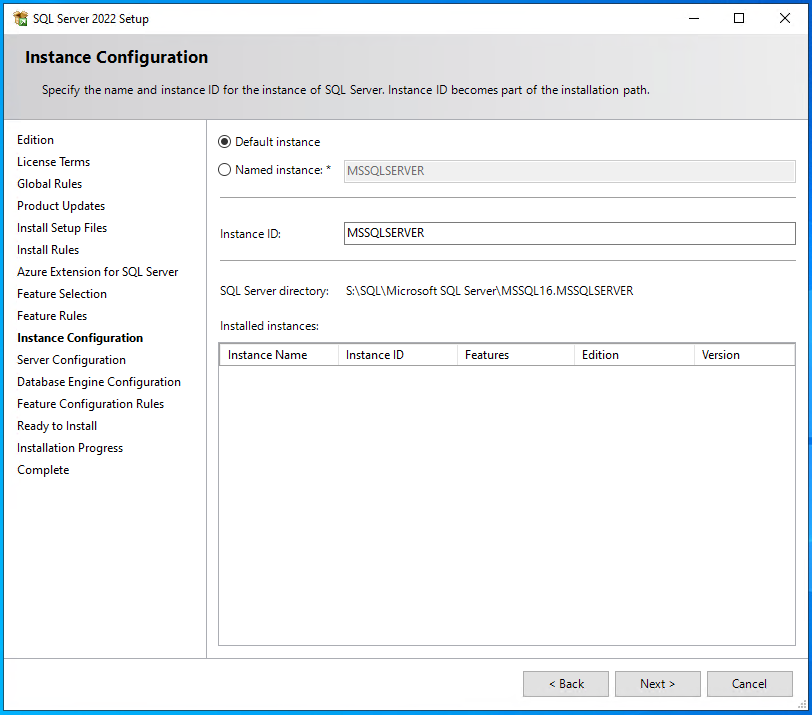
Jetzt kann die Instanz und Instanz-ID benannt werden, ich belasse beides im Standard, da auf dem Server keine weitere Instanz installiert werden wird. Danach auf <Next> klicken.
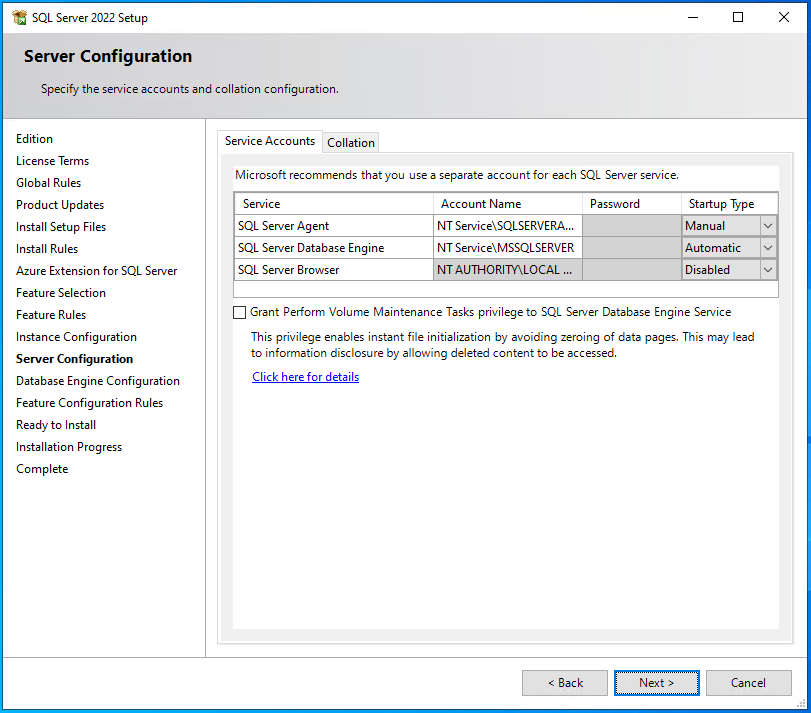
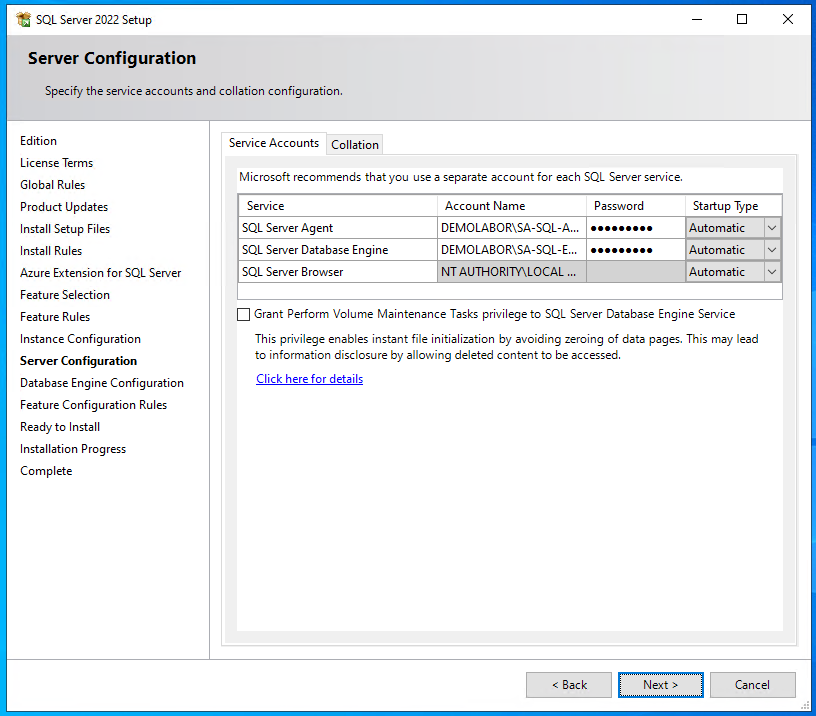
Jetzt werden die vorhin angelegten Accounts hinterlegt:
- SQL Server Agent
- Original-Account-Name: “NT Service\SQLSERVERAGENT”
- Eigener Account-Name:
- SQL Server Database Engine
- Original-Account-Name: “NT Service\MSSQLSERVER”
- Eigener Account-Name:
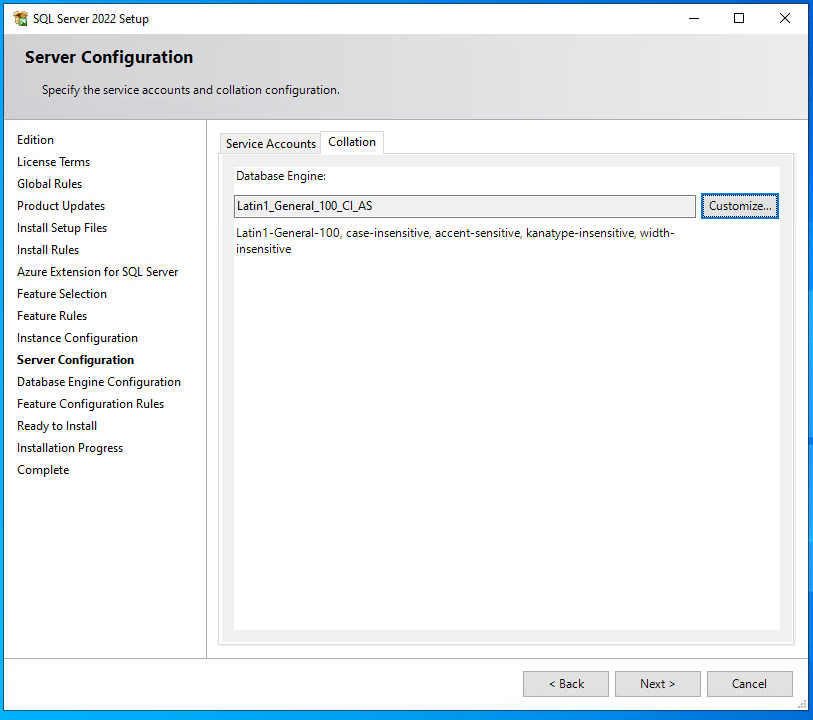
Im Reiter “Collation” die “Database Engine” auf “Latin1_General_100_CI_AS” stellen, dann auf den Button <Next> klicken.
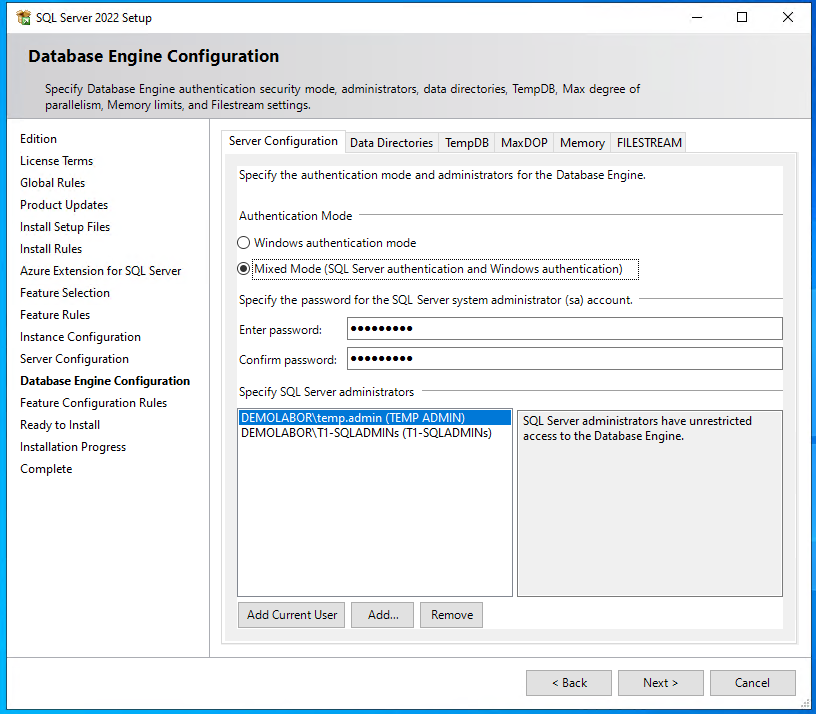
In der “Database Engine Configuration” wird:
- im Reiter “Server Configuration” der “Authentication Mode” auf “Mixed Mode” gestellt und ein Passwort hinterlegt, zudem SQL-Administratoren hinterlegt (bspw. der aktuelle Benutzer, der das Setup ausführt, und optimalerweise eine AD-Gruppe – ich habe hier die AD-Gruppe “T1\SQLADMINs” aus der Anleitung “Installation SQL-Server (standalone)” verwendet).
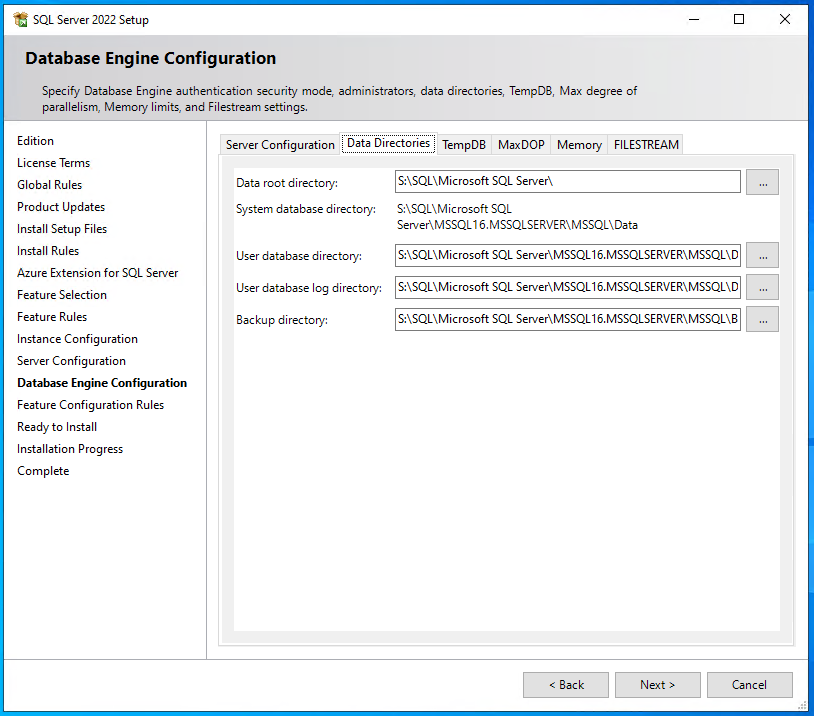
- im Reiter “Data Directories” bleiben die Pfade, wie vorgegeben, da im aktuellen Beispiel nur eine Datenfestplatte (S: -> SQL-Server) verwendet wird. Die Pfade sind dann also (von oben nach unten gelistet):
- S:\SQL\Microsoft SQL Server\
- S:\SQL\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\Data
- S:\SQL\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\Data
- S:\SQL\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\Backup
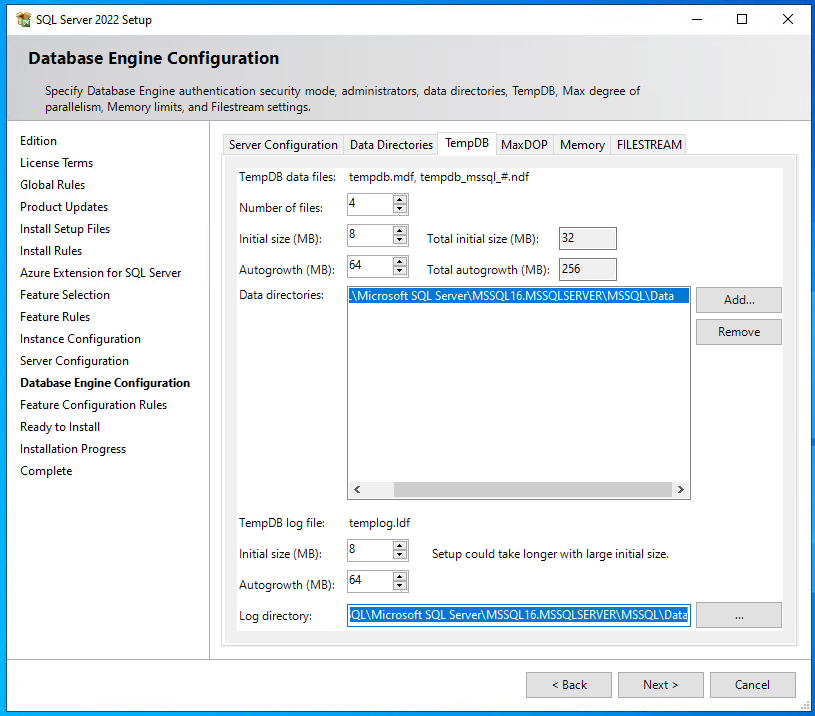
- im Reiter “TempDB” lasse ich im Beispiel die Werte & Pfade ebenfalls, wie vorgegeben. Bei größeren Umgebungen (egal, ob PROD oder eine prod-analoge Testumgebung) sollte hier realistische Werte verwendet werden. Die Werte & Pfade sind dann also (von oben nach unten gelistet):
- TempDB data files:
- Number of files: 4
- Initial size: 8
- Autogrowth: 64
- Data Directories: S:\SQL\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\Data
- TempDB log file:
- Inital size: 8
- Autogrowth: 64
- Log Directories: S:\SQL\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\Data
- TempDB data files:
- im Reiter “MaxDOP” bleibt es bei der Standard-Einstellung
- im Reiter “Memory” kann im Beispiel die Standard-Einstellung belassen werden, da auf dem System sonst nichts weiter laufen wird. In einer PROD-/TEST-Umgebung sollten die Werte realistisch eingestellt werden.
- im Reiter “FILESTREAM” wird nichts aktiviert
Danach wieder auf den Button <Next> klicken, um zum nächsten Schritt zu gelangen, welcher lediglich eine Zusammenfassung aller Settings ist und mit einem Klick auf den Button <Install> wird die eigentliche Installation dann gestartet, welche durchaus bis zu 20 Minuten in Anspruch nehmen kann (hängt von den Ressourcen des Servers und den zu installierenden Komponenten ab).
Nach Abschluss der Installation kann auf den Button <Close> geklickt werden. Es sollten natürlich alle Setup-Schritte mit einem grünen Haken als erfolgreich markiert sein 😉

Installation Management Studio
Für die Anlage der ersten Datenbank wird zur besseren/einfacheren Administration das “SQL Management Studio” verwendet. Über das Setup kann mit Hilfe des Punktes “Install SQL Server Management Tools” der Download durchgeführt werden (man wird auf die Webseite weitergeleitet: Download SQL Server Management Studio (SSMS) – SQL Server Management Studio (SSMS) | Microsoft Learn). Derzeit aktuell ist die Version 19.0.1 (Build 19.0.20200.0; release 2. Februar 2023).
Die Installation des Management Studios ist recht einfach. Das Setup selbst schlägt vor, dass in den PFad “C:\Program Files (x86)\Microsoft SQL Server Management Studio 19” installiert wird. Ich persönlich installiere es immer gerne mit zum SQL-Server, also im Artikel hier dann “S:\SQL\Microsoft SQL Server Management Studio\v19”, mehr kann gar nicht eingestellt werden. Anschließend ist ein Neustart notwendig – hier bedenken, dass nicht beide Server gleichzeitig neugestartet werden, sonst stoppt das Cluster 😉


Grundkonfiguration SQL-Dienst
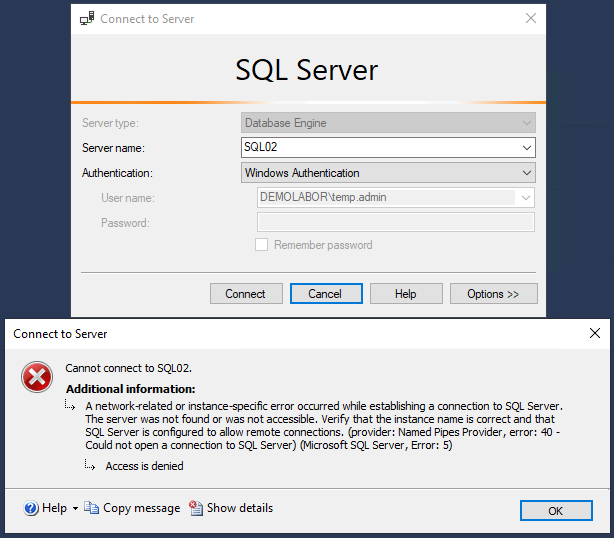
Damit beide SQL-Server gegenseitig erreichbar sind (bspw. via MGMT-Studio), müssen noch ein paar Einstellungen vorgenommen werden.
Der Anmeldeversuch über das MGMT-Studio vom SQL01 zum SQL02 bringt eine Fehlermeldung, die besagt, dass keine Verbindung hergestellt werden kann.
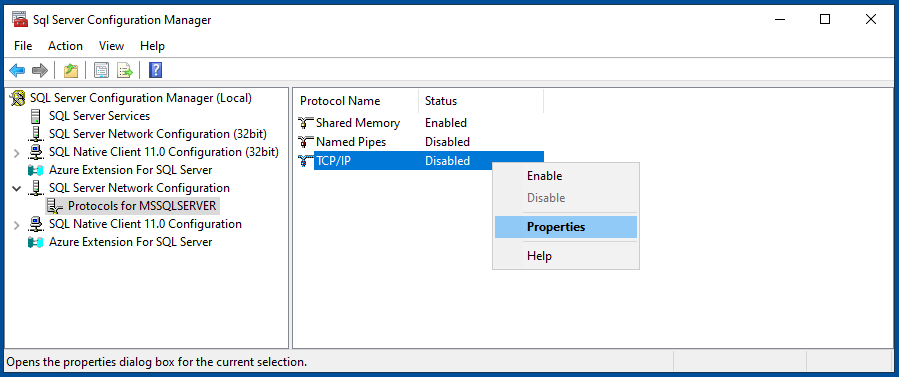
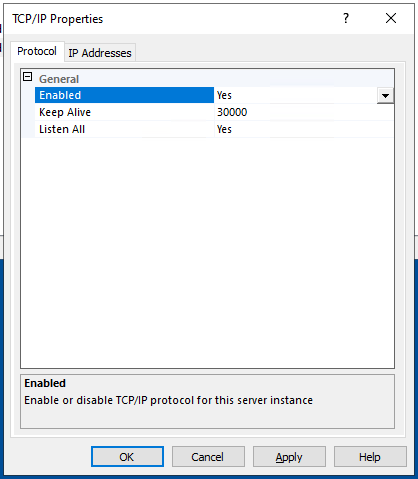
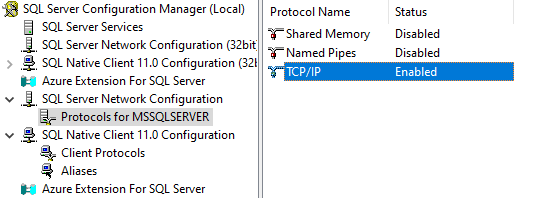
Im Startmenü den “SQL Server Configuration Manager” starten und auf der linken Seite “SQL Server Network Configuration > Protocols for MSSQLSERVER” wechseln. Dort dann auf der rechten Seite die Option “TCP/IP” bearbeiten.
Im Reiter “Protocol” die Option “Enabled” auf “Yes” stellen. Im Reiter “IP Addresses” prüfen, dass die IPv4-Adressen alle auf “Active = Yes” stehen.

Anlegen einer Dummy-DB
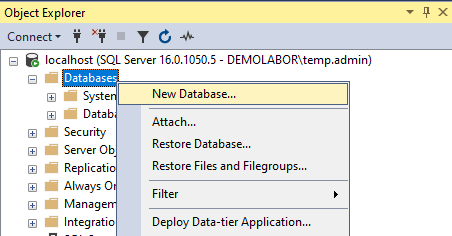
Zum Anlegen einer neuen Datenbank einfach im “Object Explorer” einen Rechtsklick auf “Databases” machen und im Kontextmenü dein Eintrag “New Database…” auswählen. Zuerst einen Namen für die neue Datenbank eintragen (hier im Beispiel “DummyDB”); man sieht, dass in der darunterliegenden Tabelle der “Logical Name” für die DB und das Transaktionslog automatisch ausgefüllt wird. Hier kann nun auch das Wachstumsverhalten beider Datenbank-Dateien eingestellt werden. Hier muss man entsprechend der geplanten Anwendung eigenständig die passenden Werte einstellen, entweder nach Erfahrung, nach Herstellervorgaben oder manchmal schlichtweg nach Bauchgefühl.
Auf der linken Seite kann man weitere Einstellungen vornehmen, die für die Beispiel-DB aber nicht weiter relevant sind.
Möchte man eine DB-Anlage später mal automatisieren (und bspw. gewisse Werte dann auch flexibel zu Laufzeit befüllen), kann man im Menü “Script” auch ein SQL-Befehl erstellen lassen. Sowas eignet sich bspw. auch gut für Disaster-Recovery-Szenarien.
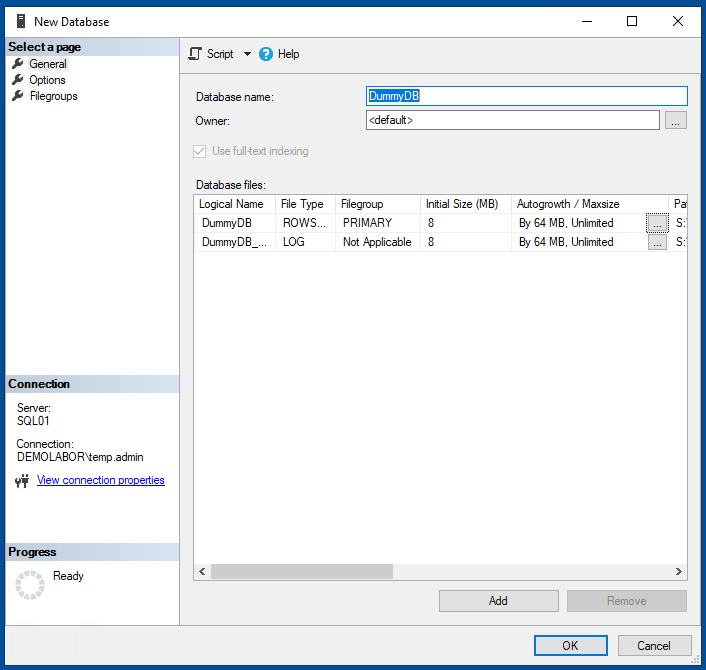
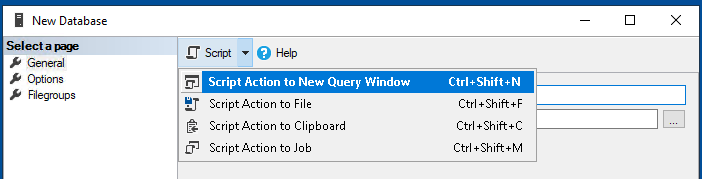
Das erwähnte SQL-Script ist ganz unten im Artikel als Download angehängt.
Erstellen der ersten Verfügbarkeitsgruppe
Diese DB soll nun mittels der Verfügbarkeitsgruppe (engl. “Availability Groups”, kurz “AGs”) auf den zweiten SQL-Server übertragen werden.
Feature aktivieren
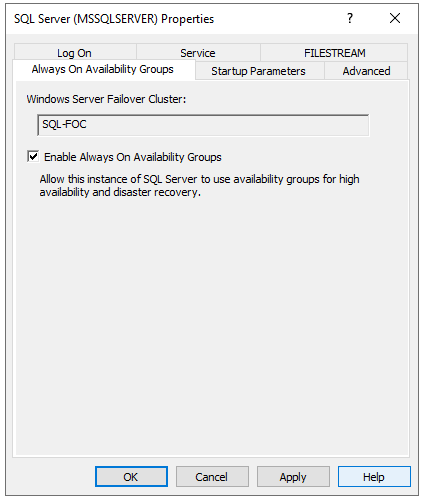
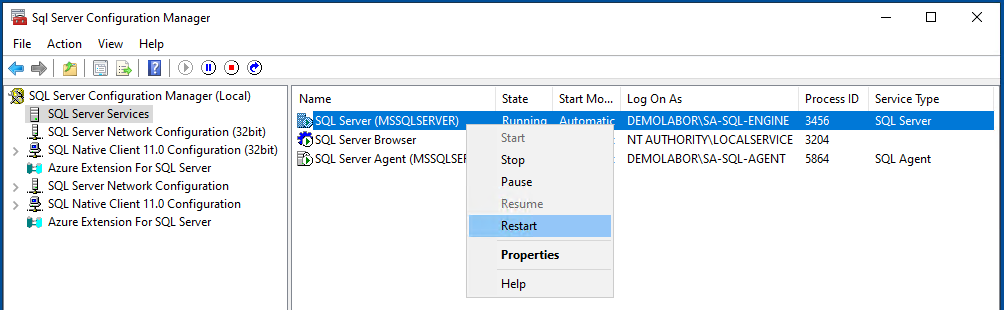
Dazu im “SQL Server Configuration Manager” in die Eigenschaften des SQL-Server Dienstes gehen und dort im Reiter “Always On Availability Groups” den Haken bei “Enable Always On Availability Groups” setzen. Dieser Vorgang muss auf beiden SQL-Servern durchgeführt werden!
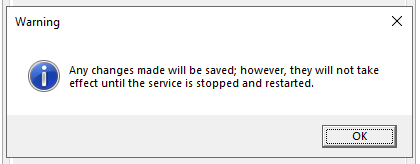
Es erscheint die Meldung, dass diese Einstellung erst nach Dienstneustart greift, weshalb der SQL-Dienst direkt neugestartet wird.
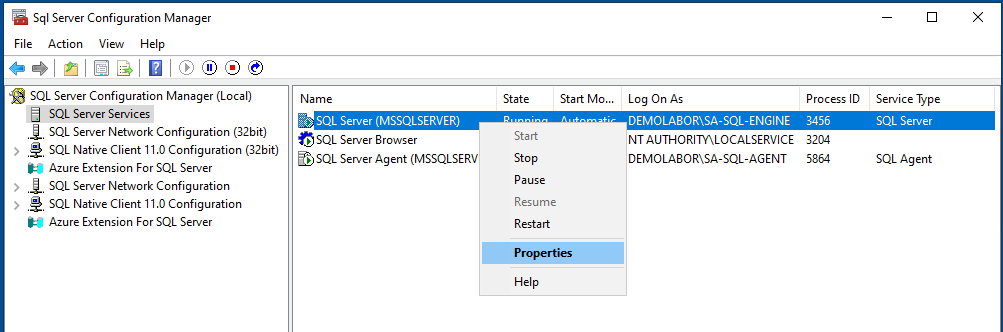
Verfügbarkeitsgruppe anlegen
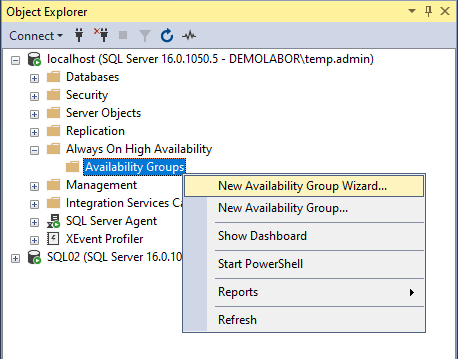
Nun kann im SQL Server Management Studio (kurz “SSMS”) die Verfügbarkeitsgruppe angelegt werden. Dazu im “Object Explorer” den Bereich “Always On High Availability” ausklappen und auf “Availability Groups” mit einem Rechtsklick und der Auswahl “New Availability Group Wizard…” den Assistenten starten.
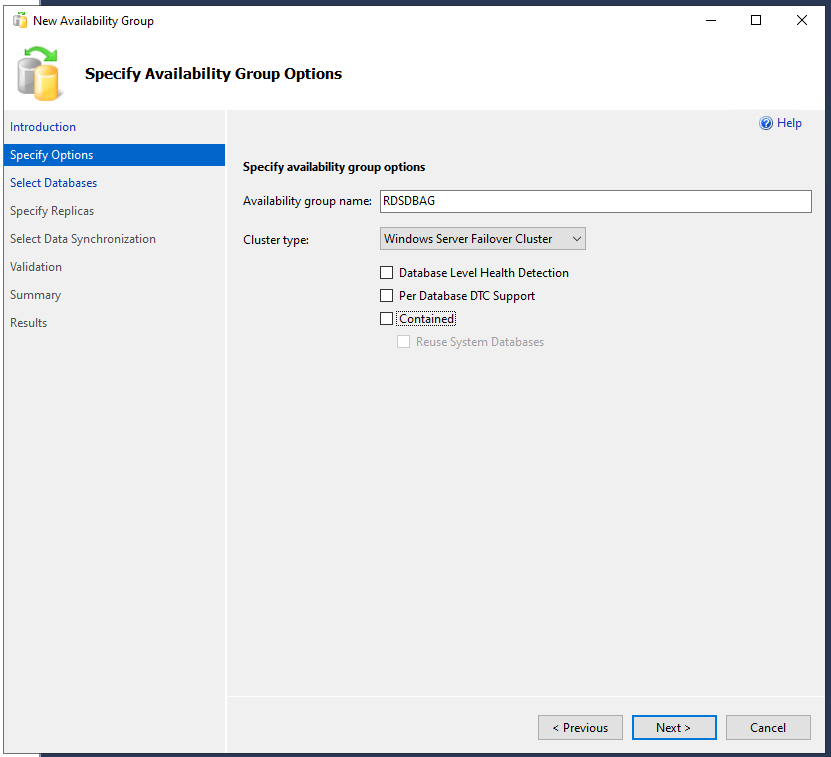
Der Einführungsdialog kann übersprungen werden, danach folgt die Eingabe des Namens der Verfügbarkeitsgruppe und die Auswahl des Clustertyps. Beim Namen wähle ich “RDSDBAG”, weil ich die Verfügbarkeitsgruppe später noch für einen anderen Artikel verwenden möchte, bei “Cluster type” wird natürlich das “Windows Server Failover Cluster” gewählt.
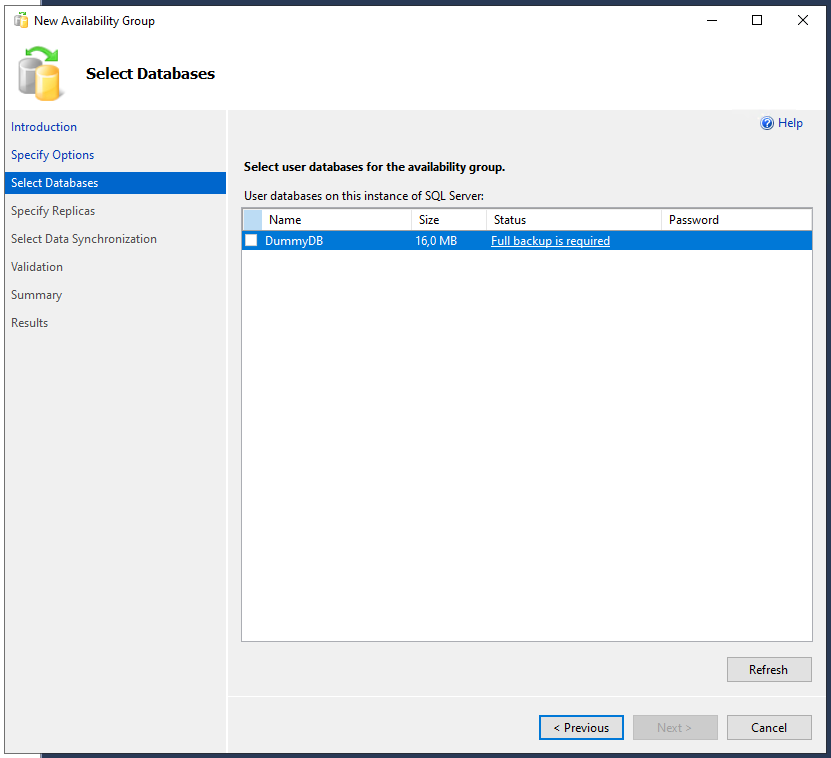
Danach wird die Datenbank ausgewählt, welche in die Verfügbarkeitsgruppe aufgenommen werden soll. Hierbei weist der Assistent direkt darauf hin, dass erstmal ein Backup dieser Datenbank erforderlich ist.
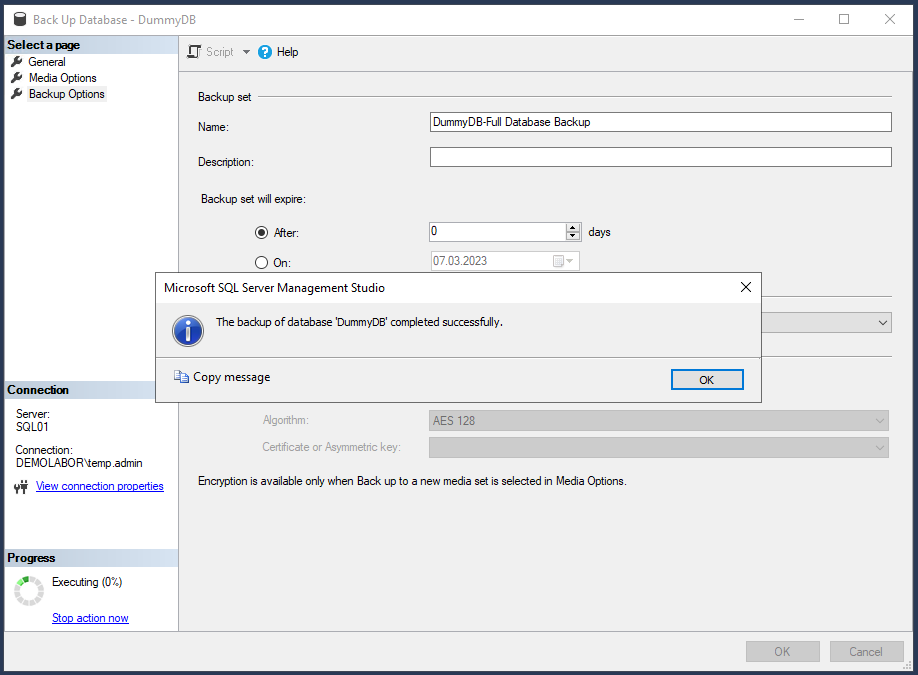
Also kurzerhand schnell ein Backup erstellen:
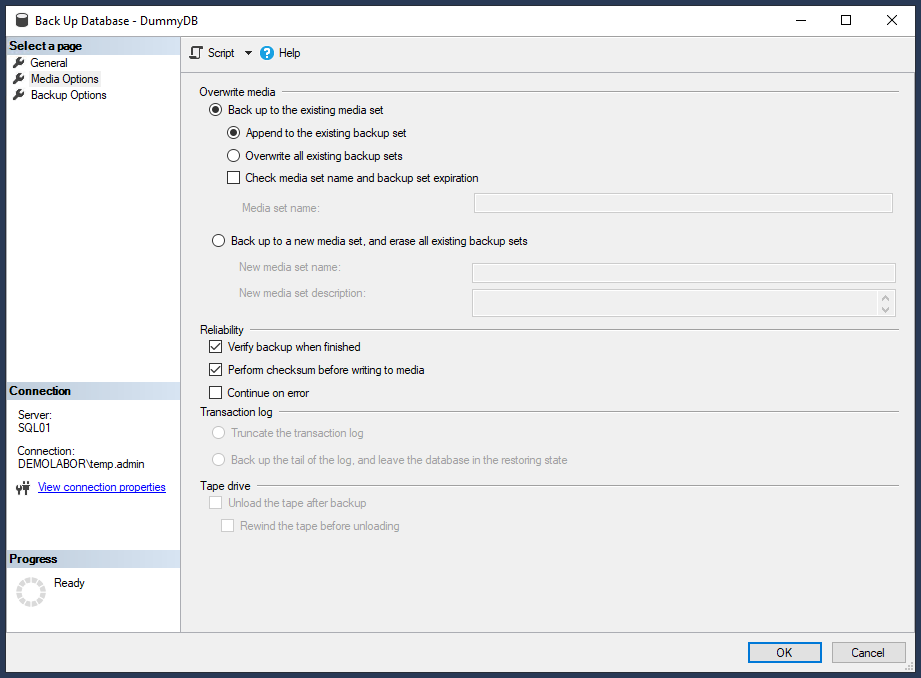
- Rechtsklick auf die Datenbank, dann im Kontextmenü “Tasks > Back Up…” auswählen
- Dann bei “General” sicherstellen, dass bei “Backup type” die Option “Full” ausgewählt ist, bei “Media Options” im Bereich “Reliability” die Haken bei “Verify backup when finished” & “Perform checksum before writing to media” gesetzt sind und bei “Backup Options” die Kompression aktiviert ist.
- Optional kann man sich das wieder als SQL-Script erstellen für automatisierte Prozesse.
- Nach einem Klick auf <OK> wird schnell das Backup erstellt (die DB ist ja noch leer)
… und weiter geht’s mit der Verfügbarkeitsgruppe – hier im Assistenten auf den Button <Refresh> klicken, sodass die Datenbank jetzt im Status “Meets prerequisites” steht und auch ausgewählt werden kann.
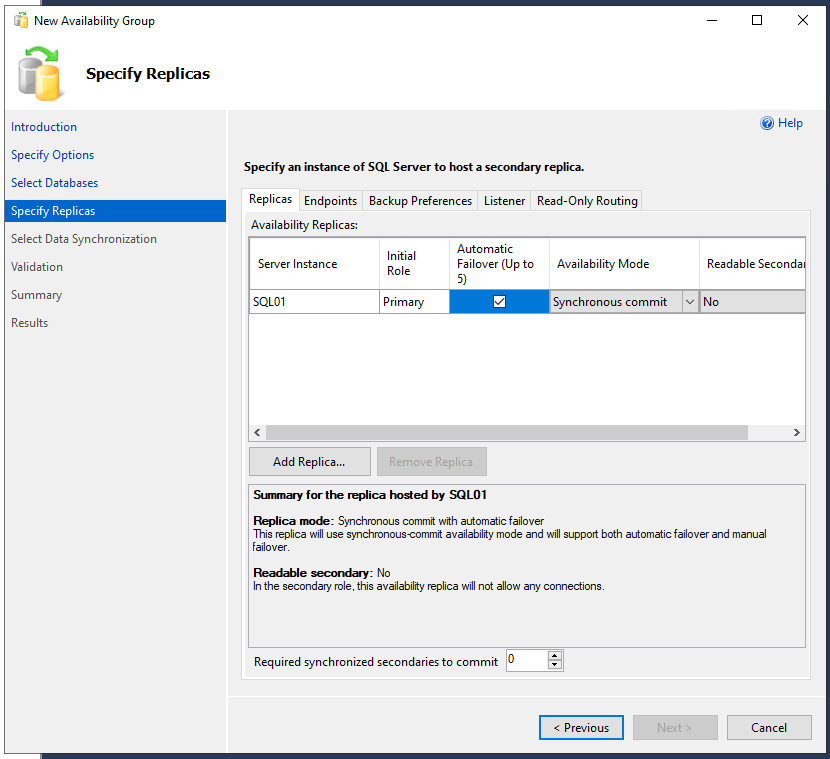
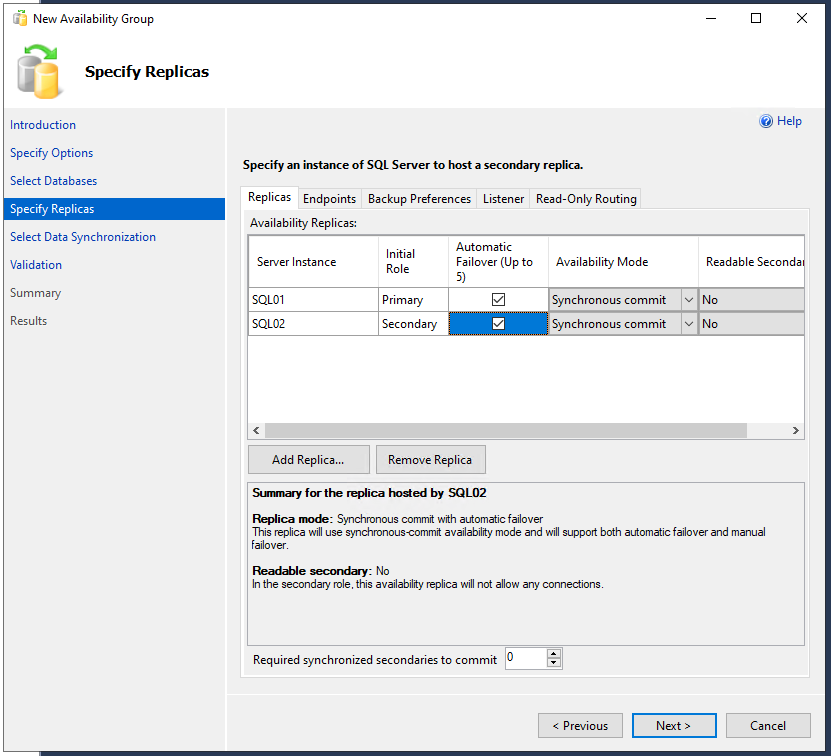
Jetzt werden die Einstellungen für die Replikate spezifiziert. An dieser Stelle wird zuerst der Haken bei “Automatic Failover” gesetzt und automatisch springt der “Availability Mode” von “Asynchronous commit” auf “Synchronous Commit” um. Über den Button <Add Replica…> wird nun der zweite SQL-Server hinzugefügt und natürlich auch der Haken bei “Automatic Failover” gesetzt.
Im Reiter “Endpoints” müssen keine Einstellungen vorgenommen werden.
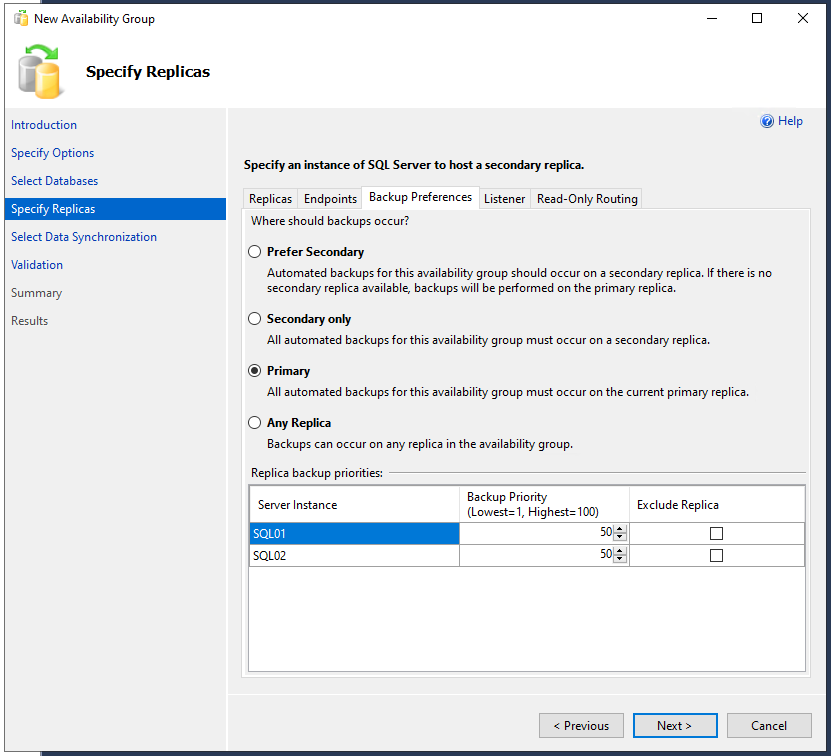
Im Reiter “Backup Preferences” kann ausgewählt werden, von welchem Replikat bzw. welchem Server das Backup ausgeführt werden soll. Bei größeren DBs mag das im Rahmen der Performance durchaus Sinn machen, wenn dies auf dem zweiten Server durchgeführt wird, allerdings sollte man dann auch sicherstellen, dass die Daten dort synchron abgelegt werden, sonst gibt’s eine Datenlücke zwischen primärer und sekundärer Datenbank und somit auch eine inhaltliche Datenlücke im Backup. Da hier im Beispiel-Artikel die Datenbank keine nennenswerte Performance bringen muss, kann “Primary” ausgewählt werden.
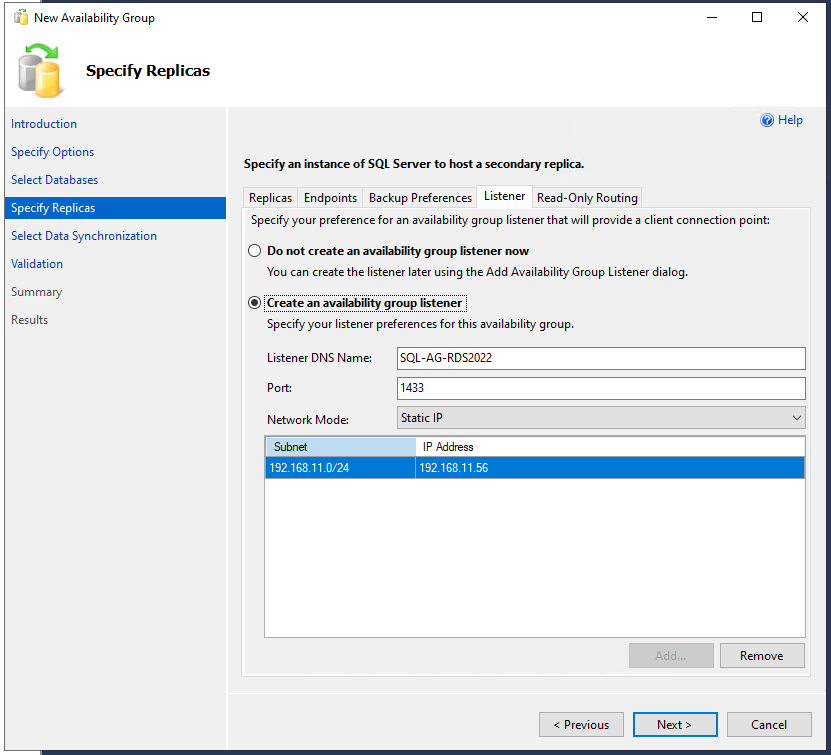
Im Reiter “Listener” wird nun der DNS-Name des “Availability group listener” vergeben. Ich trage hier “SQL-AG-RDS2022” ein, da die SQL-Server “SQL01″/”SQL02” und das Failover-Cluster “SQL-FOC” heißt und ich eine einheitliche Benamung bevorzuge, sodass man erkennt, welche Server/Dienste hinter (DNS-)Namen stecken. Als Port verwende ich den 1433 (Standardport für SQL, hier könnte man auch einen anderen verwenden, muss man aber nicht), den “Network Mode” belasse ich bei “Static IP” und trage unten die IP “192.168.11.56” ein, welche ich im Vorfeld für diesen Zweck in meiner Excel-Liste reserviert hatte.
Im Reiter “Read-Only Routing” bleiben die Einstellungen unverändert da dies hier nicht verwendet wird.
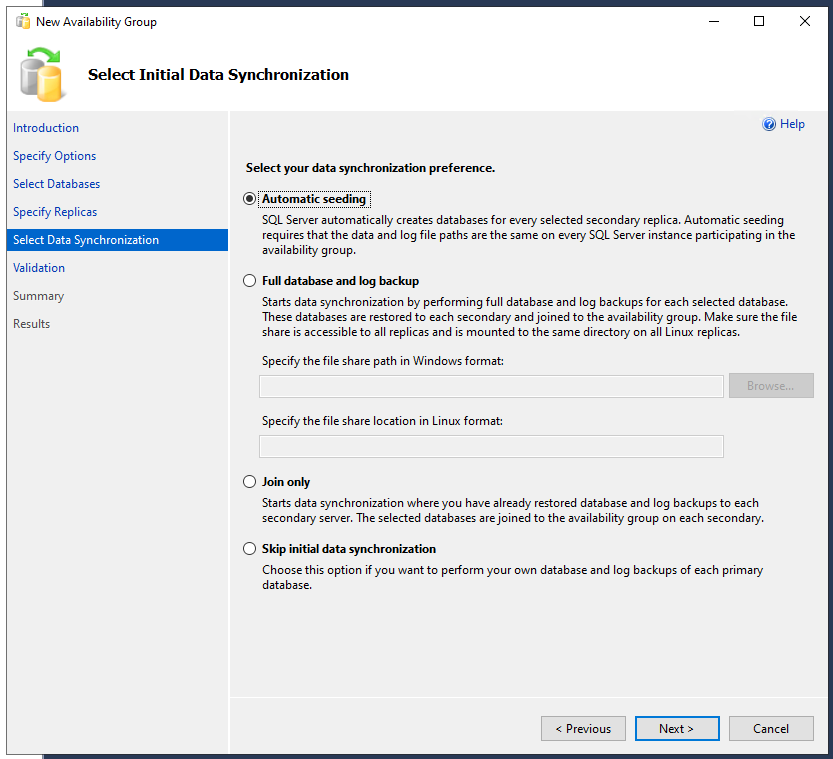
Im nächsten Schritt wird ausgewählt, wie die Daten der Datenbank initial übertragen werden sollen. Bei neuen/leeren DBs oder mit wenig Inhalt kann das auf “Automatic seeding” stehen bleiben. Wenn man eine große Datenbank (die aktiv im produktiven Betrieb/Verwendung ist) nachträglich in eine Verfügbarkeitsgruppe aufnimmt, bietet sich eines der anderen Verfahren besser an.
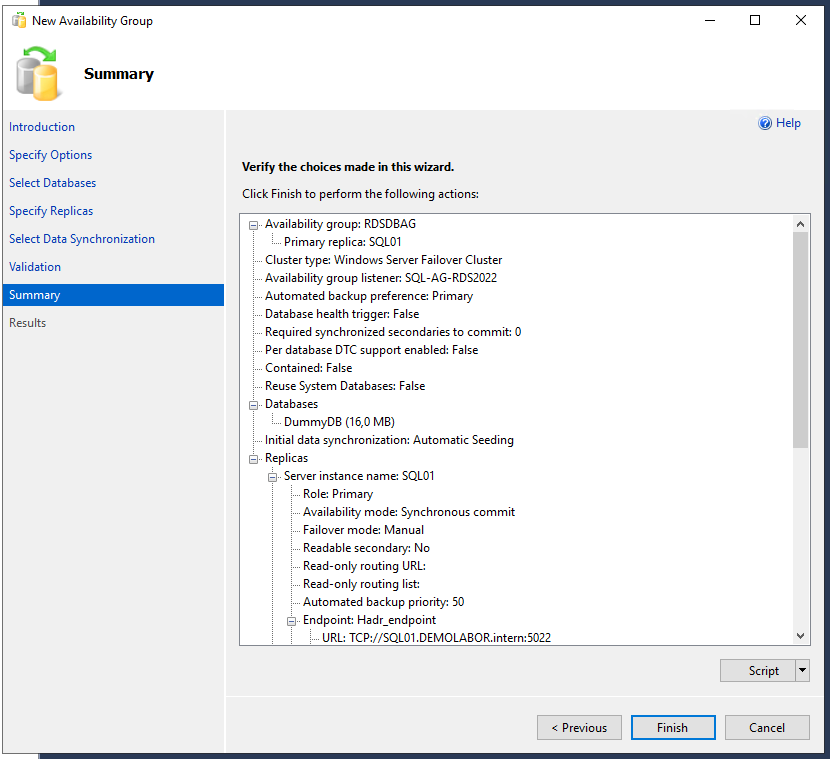
Es folgt eine kurze Prüfung aller Einstellungen, sowie danach nochmal eine Übersicht dieser Einstellungen und der Möglichkeit, das ganze wieder als SQL-Script (ganz unten im Artikel als Download angehängt) zu exportieren und dann kann mit einem Klick auf den Button <Finish> die Anlage der Verfügbarkeitsgruppe durchgeführt werden.





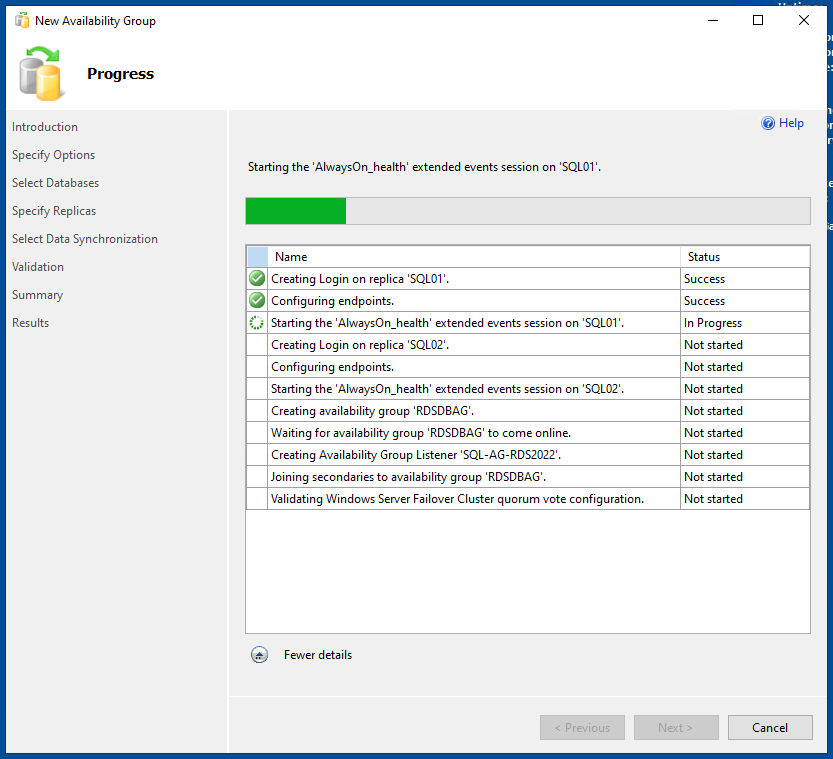
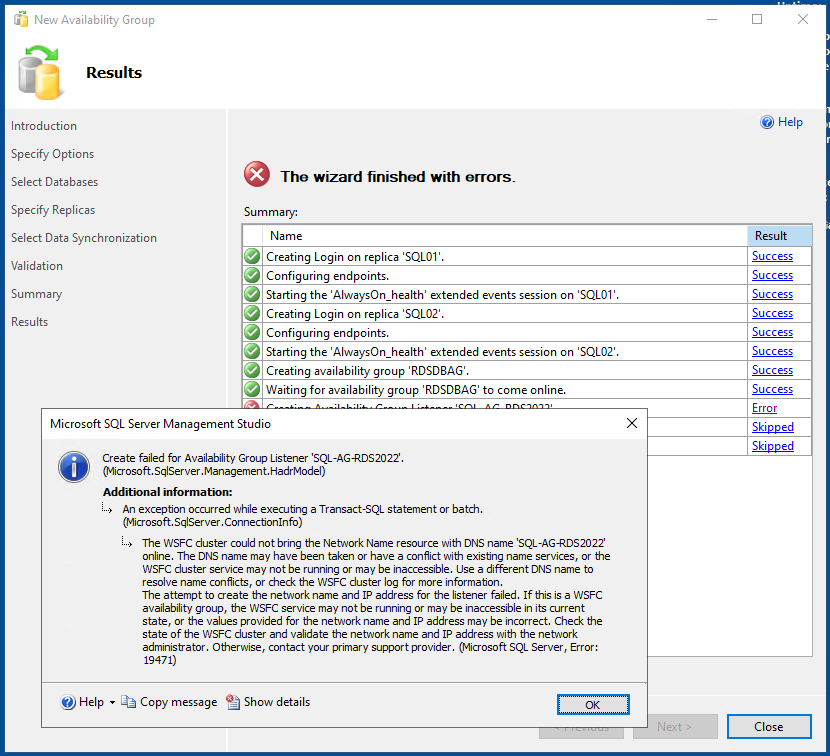
Hinweis:
In meinem Fall schlug die Anlag des Listeners fehl, weil ich bereits im DNS-Serve den DNS-Namen angelegt hatte.
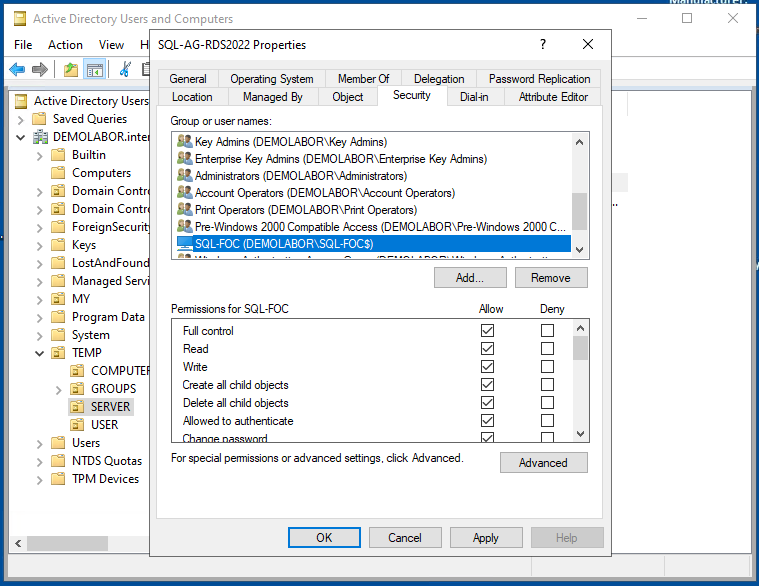
Zudem braucht das AD-Computer-Objekt “SQL-FOC$” (= Cluster) entweder das Recht “Create Computer-Objekts” auf der OU, wo es selbst liegt, oder wenn man das AD-Computer-Objekt für den SQL-Listener bereits vorher im AD angelegt hat, muss darauf das Recht “Full Control” gewährt werden.
Ich habe nun den DNS-Eintrag gelöscht, die Verfügbarkeitsgruppe entfernt, das AD-Objekt “SQL-AG-RDS2022” angelegt und dem “SQL-FOC$” darauf das Recht “Full Control” vergeben. Danach mittels des vorher erzeugten Skripts die Verfügbarkeitsgruppe erneut angelegt.
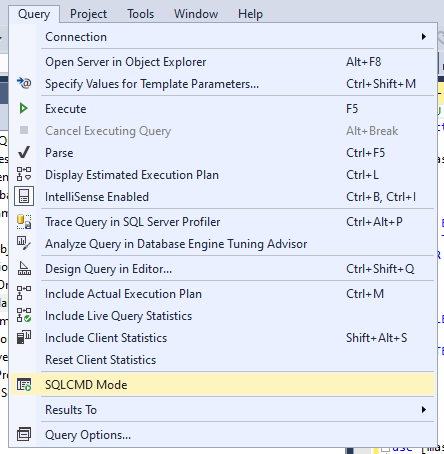
Wichtig: Für die Ausführung des Skriptes muss man im SSMS-Menü “Query” den Eintrag “SQL CMD Mode” anklicken.
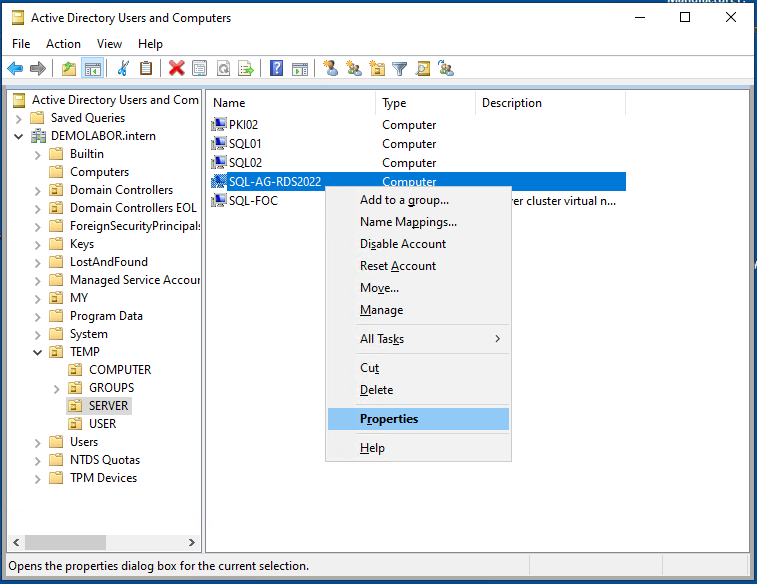
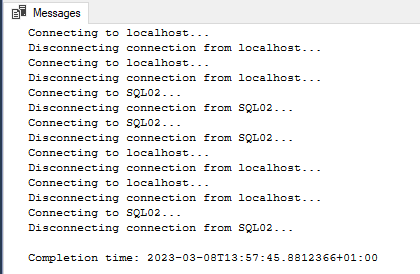
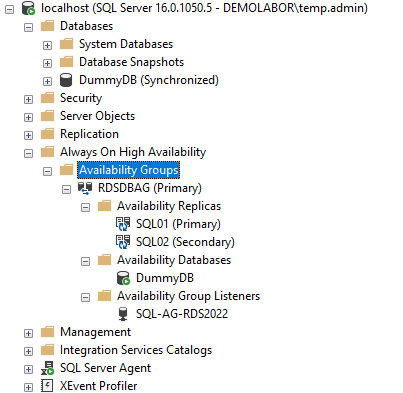
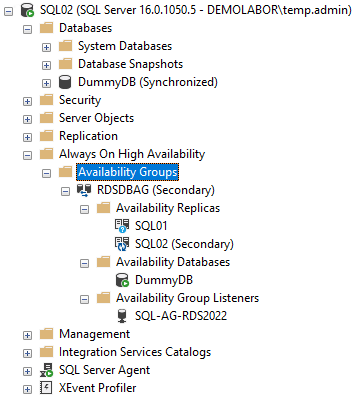
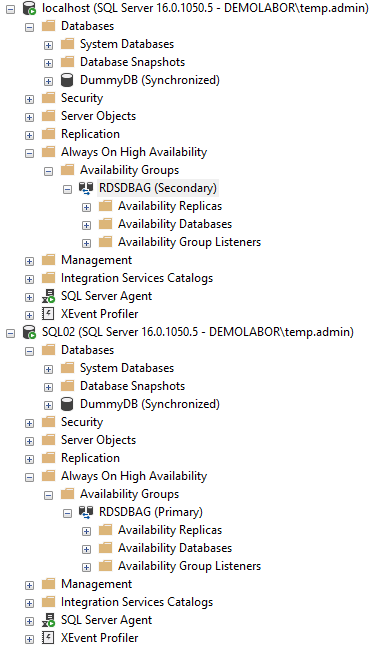
Wenn der assistant (oder das SQL-Skript) durchgelaufen sind, sieht man im SSMS dann hinter der Datenbank noch den Zusatz “(Synchronized)”, sowie im Bereich “Always On High Availability” die neuangelegte Verfügbarkeitsgruppe
Schwenken des aktiven/primären Servers
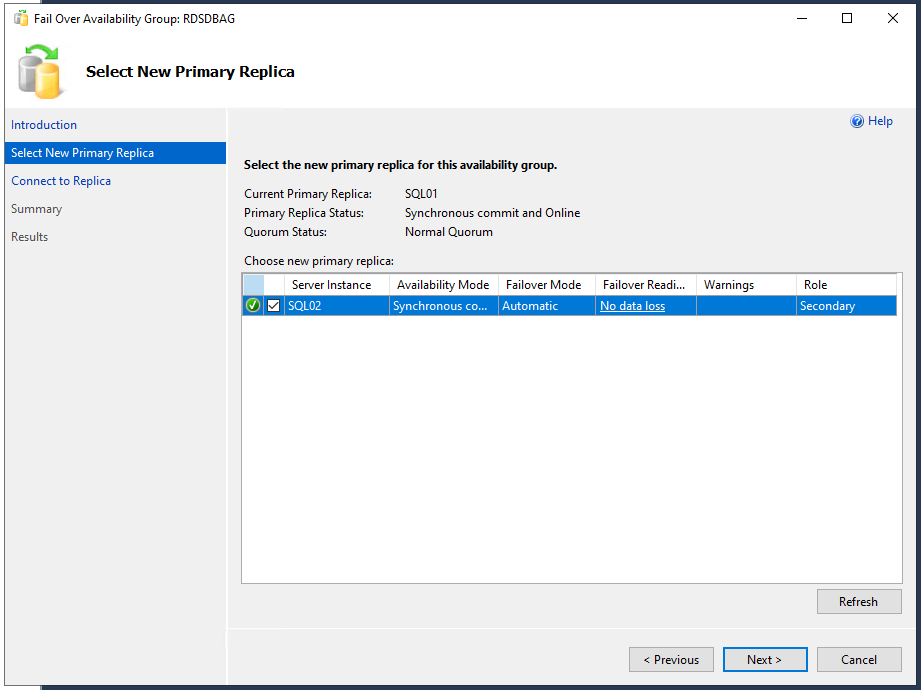
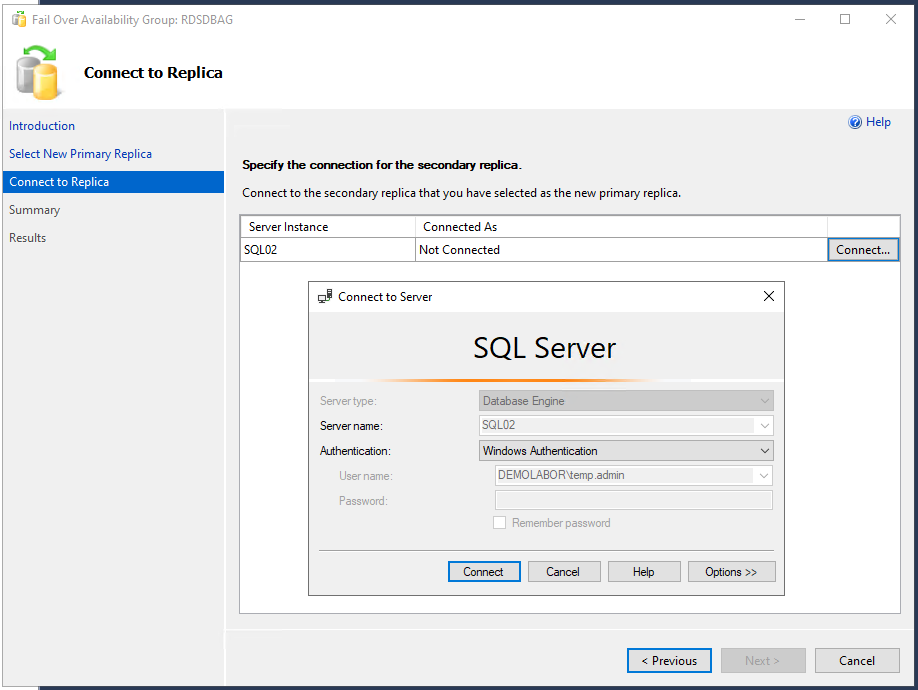
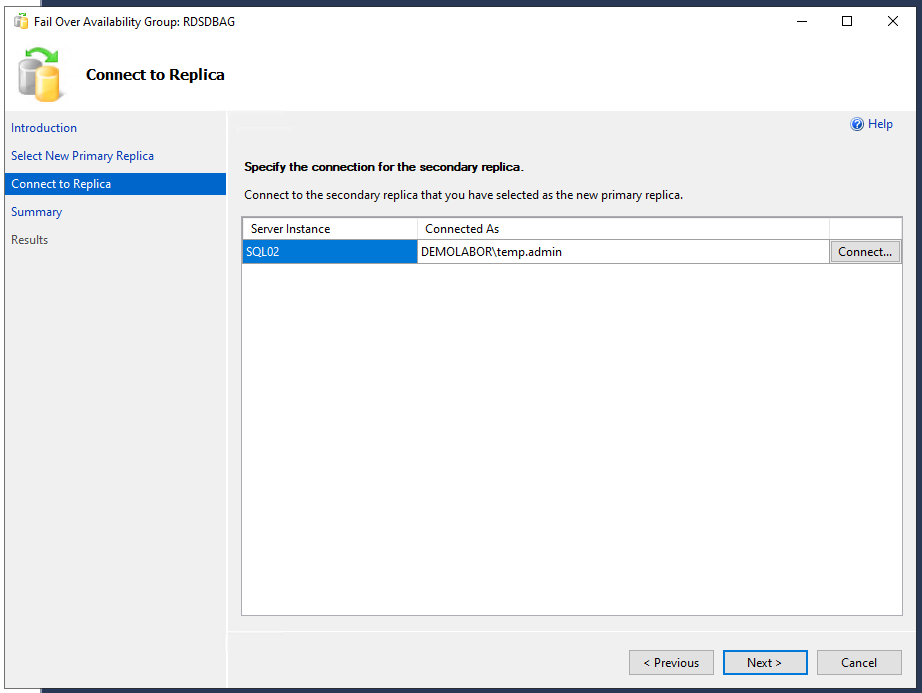
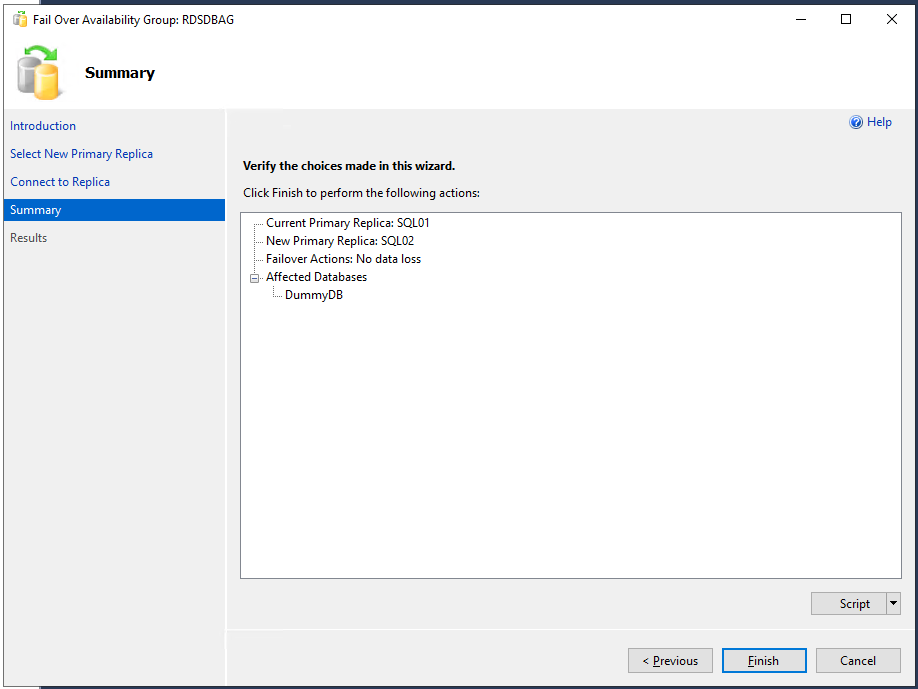
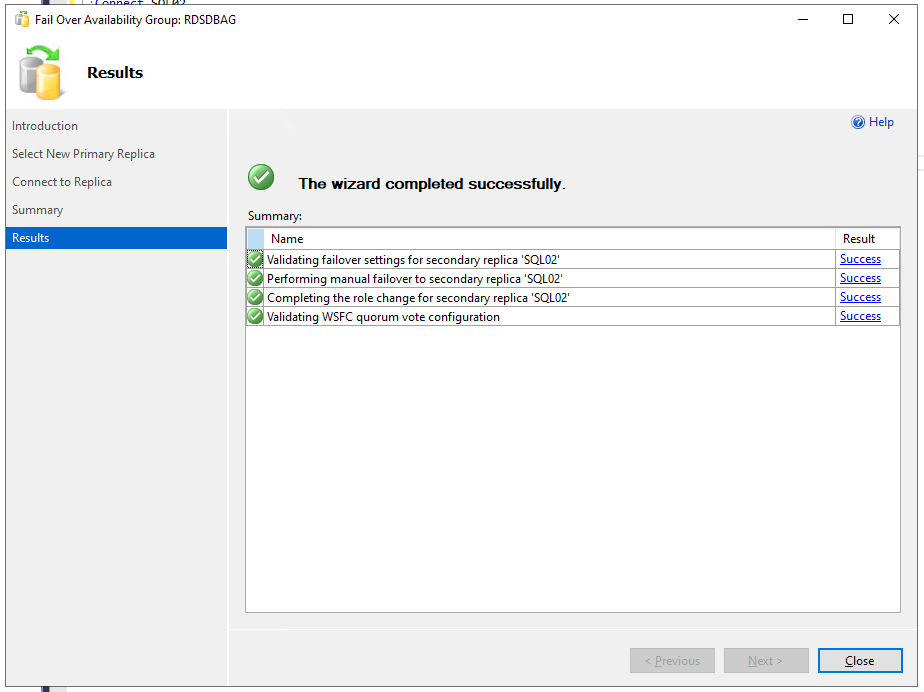
Möchte man nun die Datenbank schwenken, so macht man einen Rechtsklick auf die Verfügbarkeitsgruppe und wählt im Kontextmenü den Eintrag “Failover…” aus. Es öffnet sich eine Assistent, dessen erste Seite übersprungen werden kann. Auf der zweiten Seite sieht man die zur Verfügung stehenden Replikat-Server (hier sieht man ebenfalls den “Availabiliy Mode”, “Failover Mode” und – wichtig – der “Failover Readiness”) und kann den auswählen, auf den man schenken möchte; ein Klick auf <Next> . Danach muss man sich zu diesem Replikat-Server verbinden. Es folgt ein Übersichtsdialog, bei dem man die Möglichkeit hat, den Vorgang als SQL-Script zu exportieren. Und mit einem Klick auf den Button <Finish> erfolgt der Schwenk, welcher bei Erfolg dann auf der Ergebnisseite auch angezeigt wird.
Entsprechend ist nun im SSMS die Rollenverteilung “Secondary – Primary” zu sehen und im Failover-Manager sieht man ebenfalls auf welchem Knoten die Rolle “RDSDBAG” nun läuft.
Wichtig:
Der Schwenk sollte immer über den SQL-Server gemacht werden!


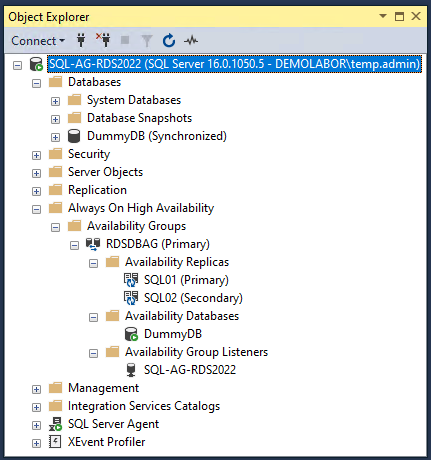
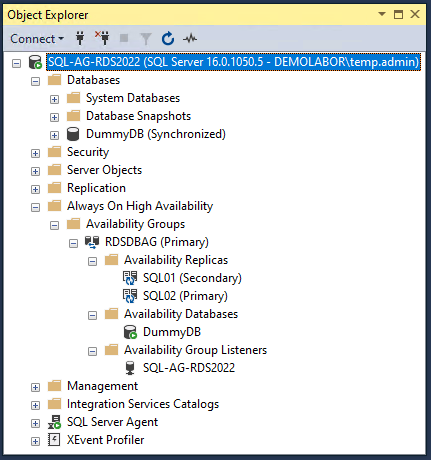
Man kann natürlich im SSMS anstelle auf den Hostnamen der jeweiligen SQL-Server auch direkt auf den SQL-Listener der Verfügbarkeitsgruppe (in dem Fall “SQL-AG-RDS2022”) verbinden und ist damit automatisch immer auf dem Primär-Server – quasi genauso, wie die Applikation, deren Datenbank auf der Verfügbarkeitsgruppe liegt.
Backup der Datenbanken der Verfügbarkeitsgruppe
Hierzu gibt es folgenden separaten Artikel: folgt noch
Downloads
- Download SQL-Server Setup: SQL Server 2022 | Microsoft Evaluation Center
- Download SQL-Server Management Studio: SQL Server Management Studio (SSMS) | Microsoft Learn
Verwendete Skripte:


Hi Ronny, sehr schöner Artikel.
Verstehe ich es richtig, dass wenn der Witness Server noch dazu kommt, dass dann das FOC mit über den Witness gezogen wird, und dann auch die AG (Verfügbarkeitsgruppe)? Auf jeden Fall ein sehr hilfreicher Artikel.
Danke Dir und viele Grüße,
Marvin
Hallo Marvin,
vielen Dank für deinen Kommentar.
Der Witness dient als “unabhängiger Zeuge” und ist dann wichtig, falls ein Knoten (bei einem Cluster aus gerader Knotenanzahl) ausfällt. Dann kann der verbliebene Knoten versuchen den Witness zu erreichen und erkennt dadurch, dass er nicht isoliert steht; der Dienst wird auf diesem Knoten dann weiterbetrieben.
VG
Ronny